
こんにちは。CData Software Japan リードエンジニアの杉本です。
この前このBlogで紹介したCData Sync の Amazon S3 Destination 連携ですが、今回新しい機能が追加されたので紹介したいと思います。
www.cdatablog.jp
通常Amazon S3 Destination は「Bucket」の接続プロパティに指定したフォルダに対して、CSVファイルを吐き出します。
吐き出すパターンとしては、以下のようにテーブル名でフォルダを作成して、その中にCSVを吐き出すパターンか
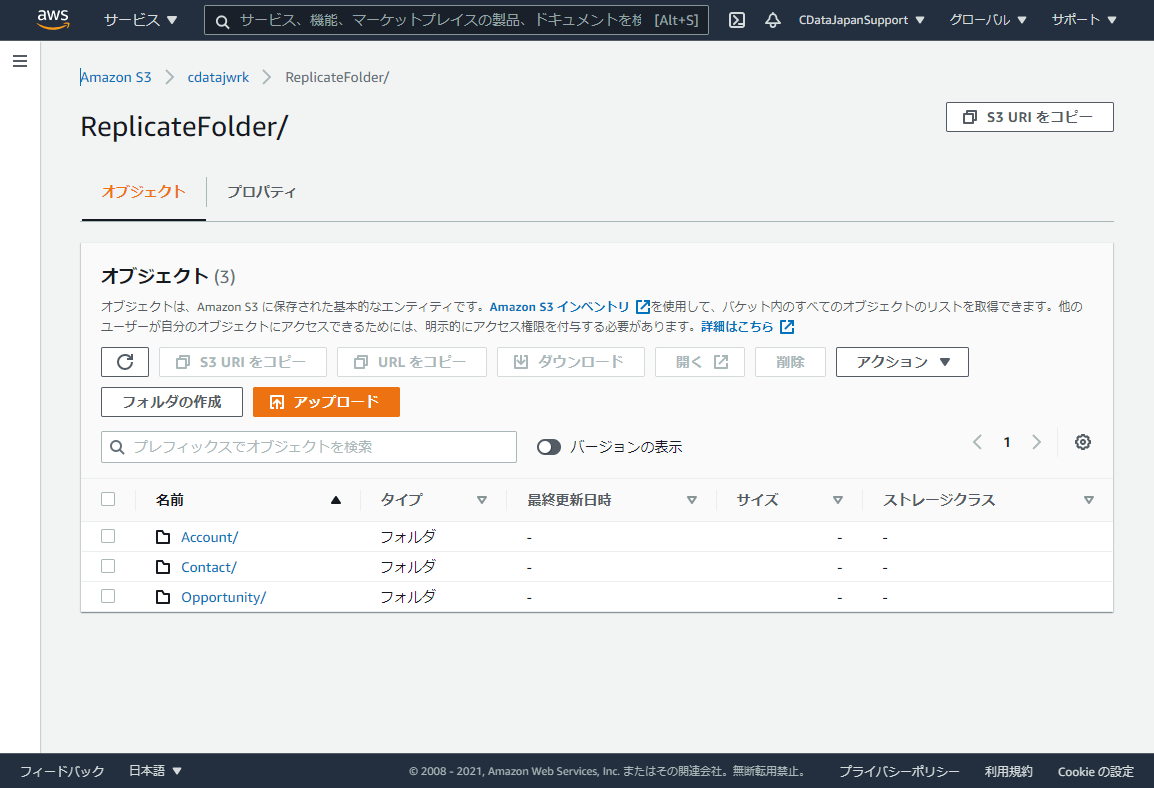
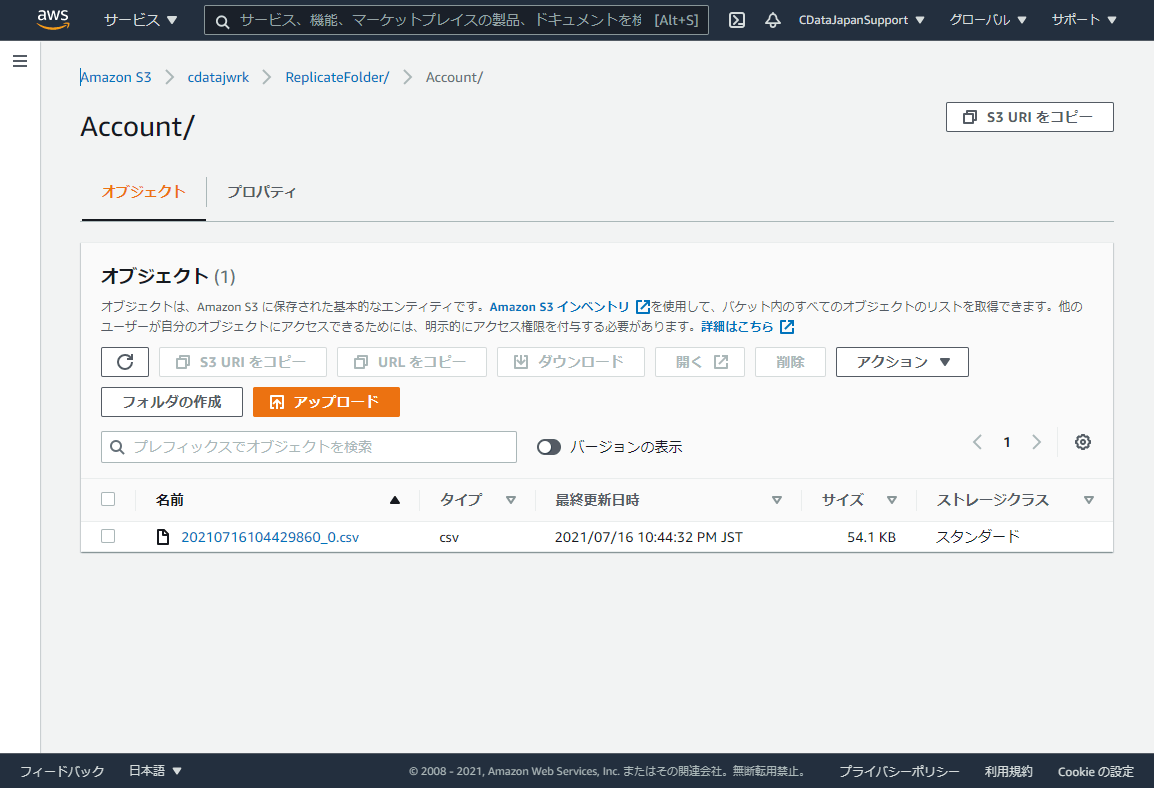
対象のBucketに直接テーブル名のCSVを吐き出すパターンの2種類です。
ただ、ユースケースとしては各テーブルを任意のフォルダに連携させたい、ということもあるでしょう。
通常であれば、Amazon S3 Destinationの接続を複数作成する方法も考えられますが、CDataSyncがConnection数ベースのライセンス形態であるため、あまり数多くのConnectionを作ることができない場合もあると思います。
また、管理も少し面倒ですよね。
そこで今回は新しく追加された機能「相対パスによるレプリケーションのサポート」でそういったケースに対応する方法を紹介したいと思います。
シナリオ
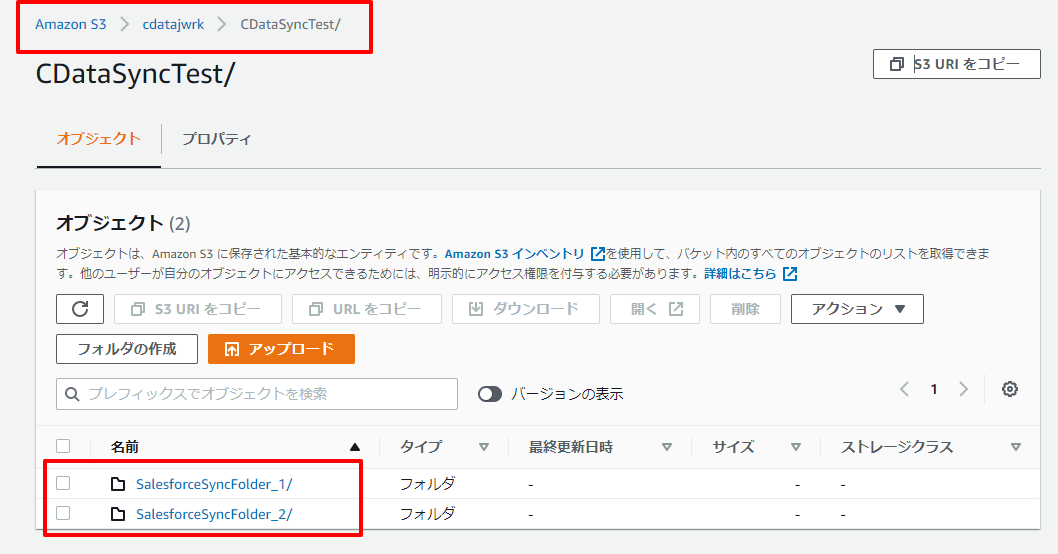
例えば、下記2種類「SalesforceSyncFolder_1」「SalesforceSyncFolder_2」のフォルダーにそれぞれCSVを出力したい、という想定で試してみましょう。
使い方
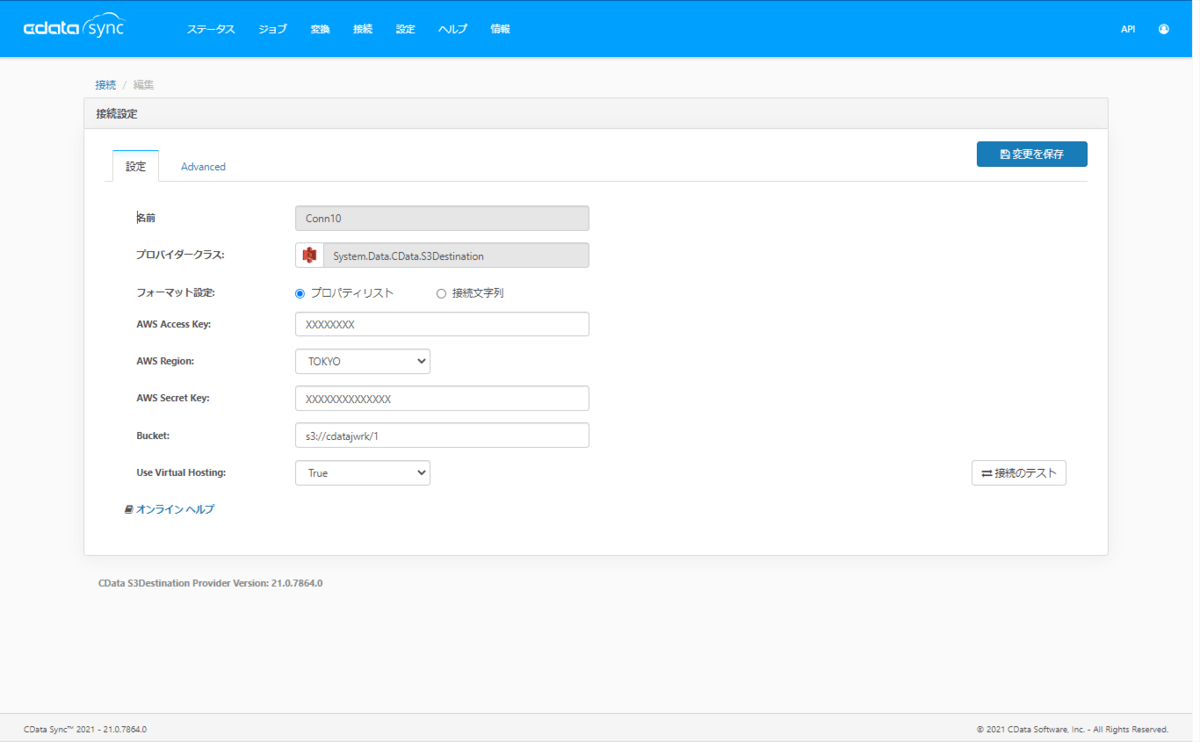
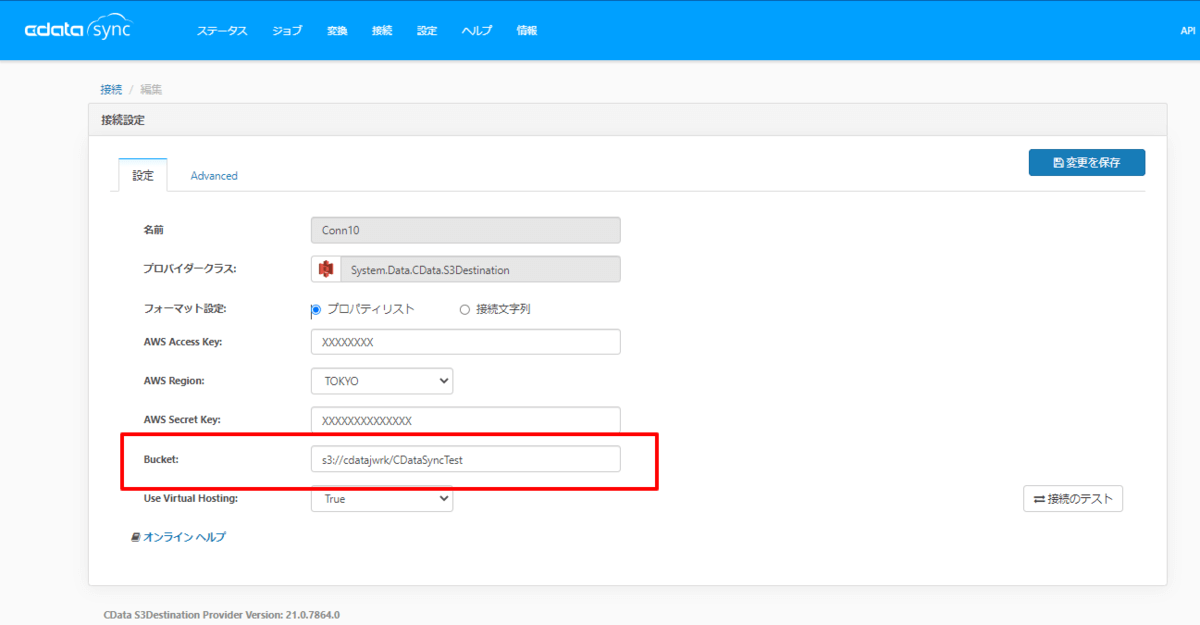
まず以前の記事で紹介したように、Amazon S3 Destination の接続を構成します。
Bucketはフォルダ分けをするルートになる「s3://cdatajwrk/CDataSyncTest」を指定します。
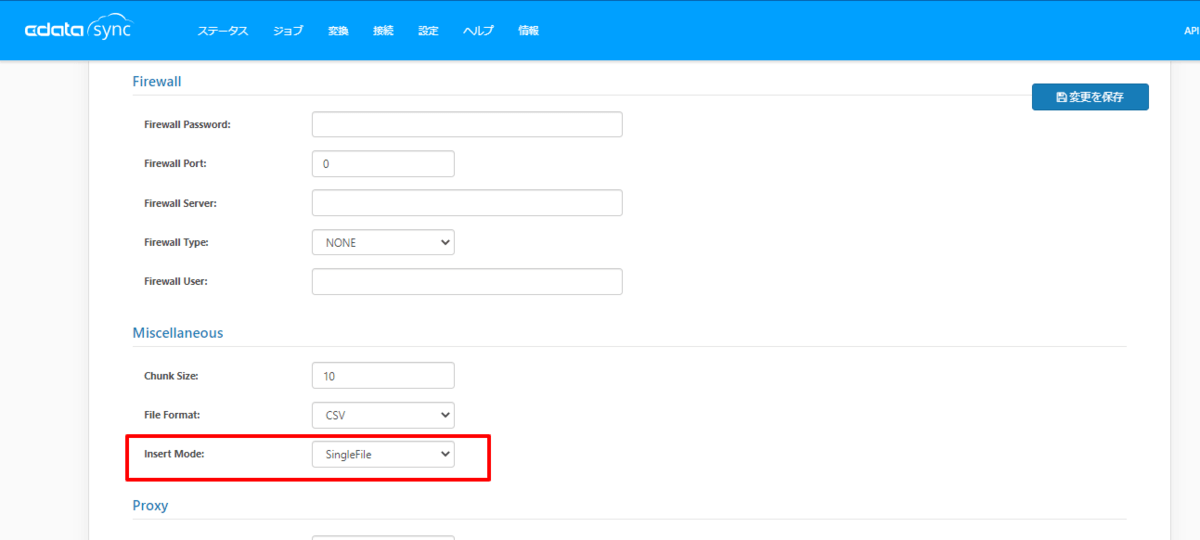
また、今回はわかりやすいようにInsert Mode を「SingleFile」にしました。これで指定フォルダにCSVファイルが直接出力されます。
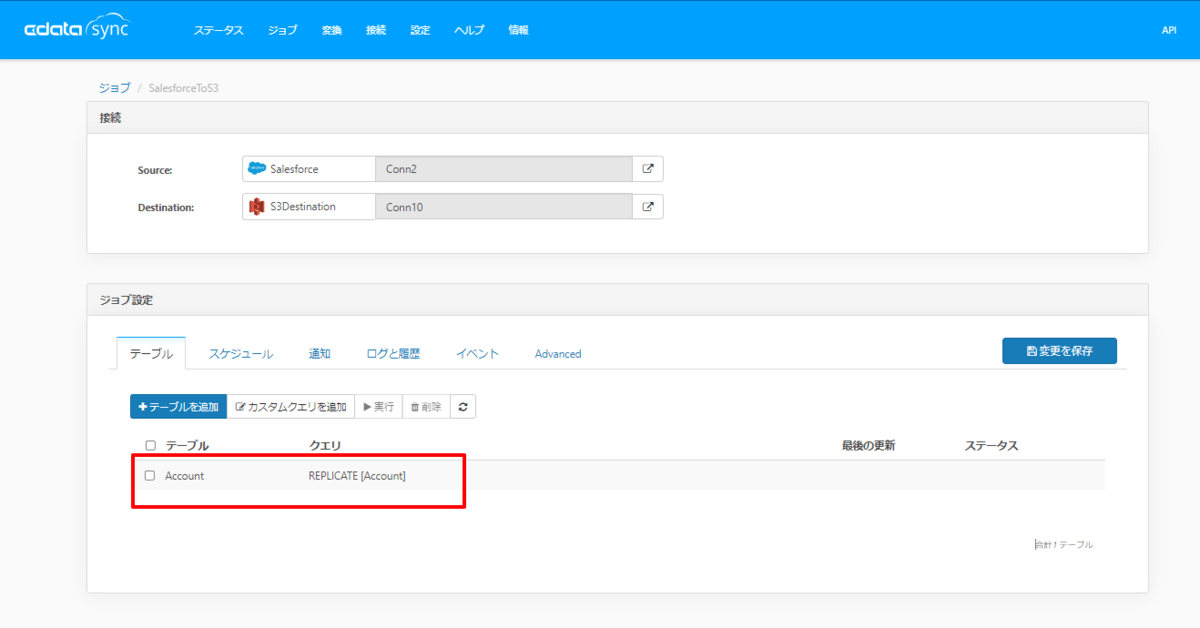
接続設定が完了したら、ジョブを作成しましょう。
前回と同様にSalesforceからデータを取得します。対象テーブルは「Account」にしました。
テーブルを登録したら、テーブル名をクリックして、「タスク設定」を開きます。
「一般」タブにある「新規テーブルを作成」をクリックして、
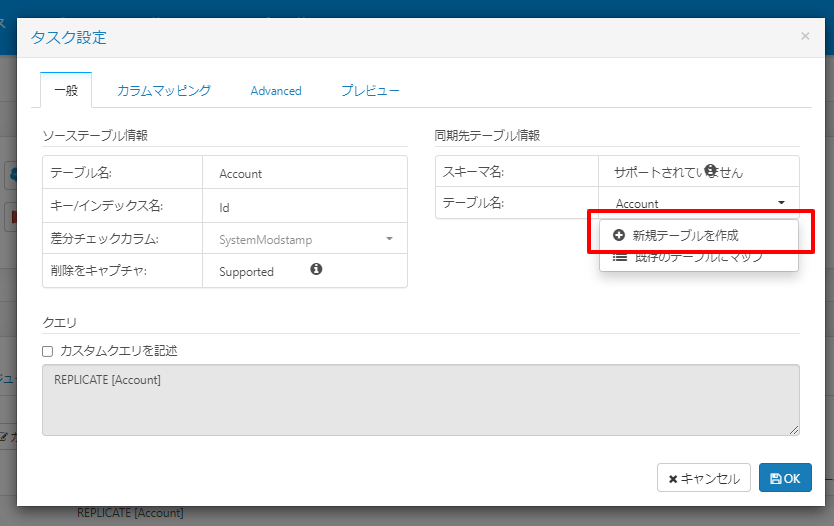
以下のように出力したいフォルダパスを追加します。この際、接続設定で指定した「Bucket」の相対パスを指定しますので、「s3://cdatajwrk/CDataSyncTest」以降のフォルダになります。
「SalesforceSyncFolder_1/Account」
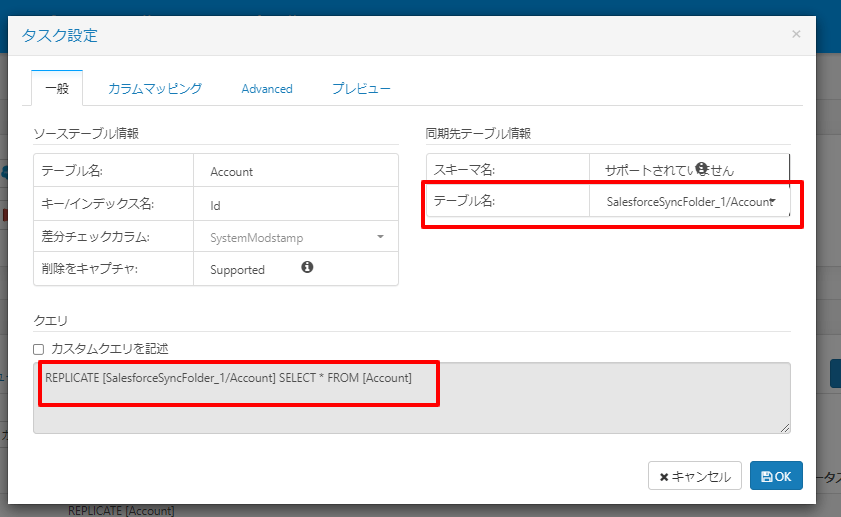
同じように「SalesforceSyncFolder_2/Account」のテーブルも追加しました。
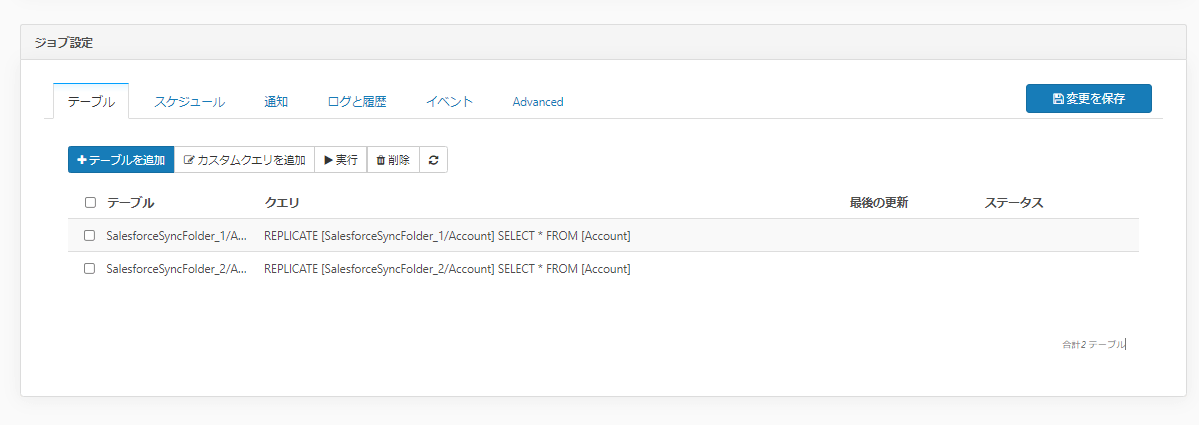
それでは実行してみましょう。対象のテーブルを選択して「実行」をクリックします。
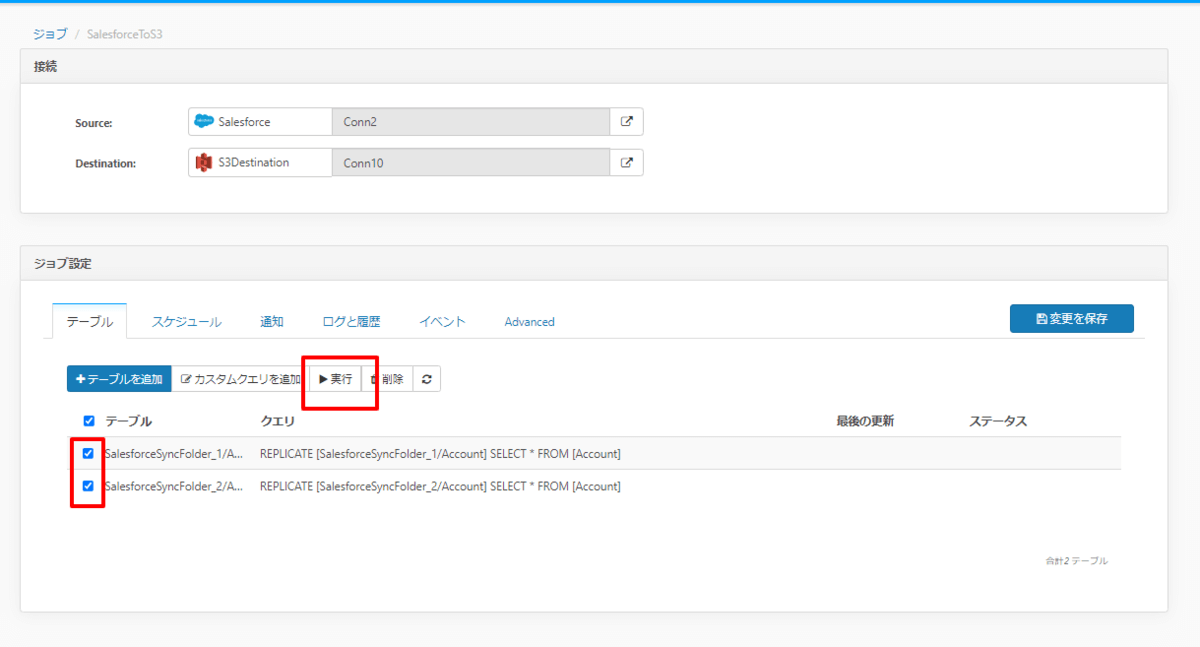
以下のように処理が正常に完了しました。
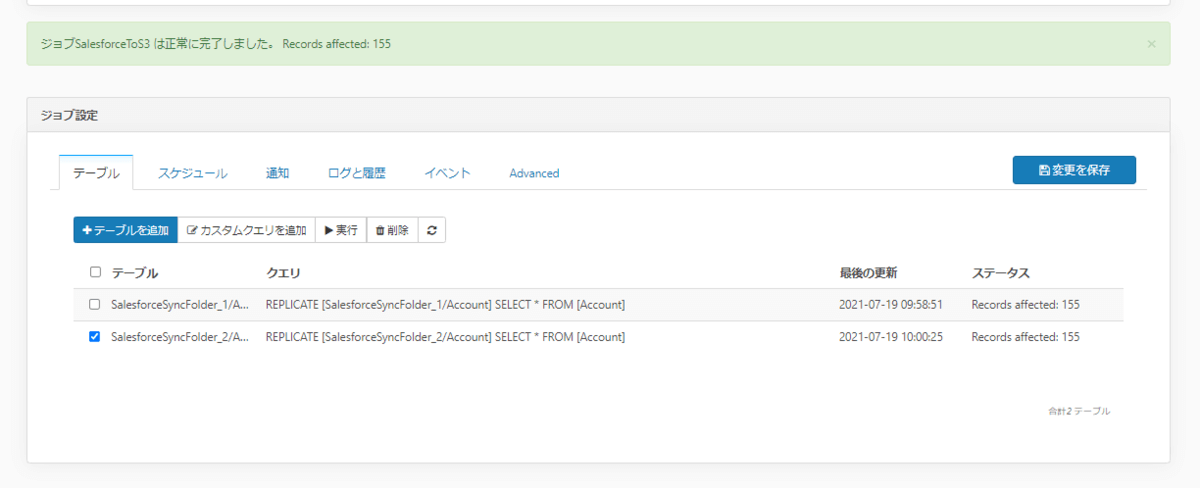
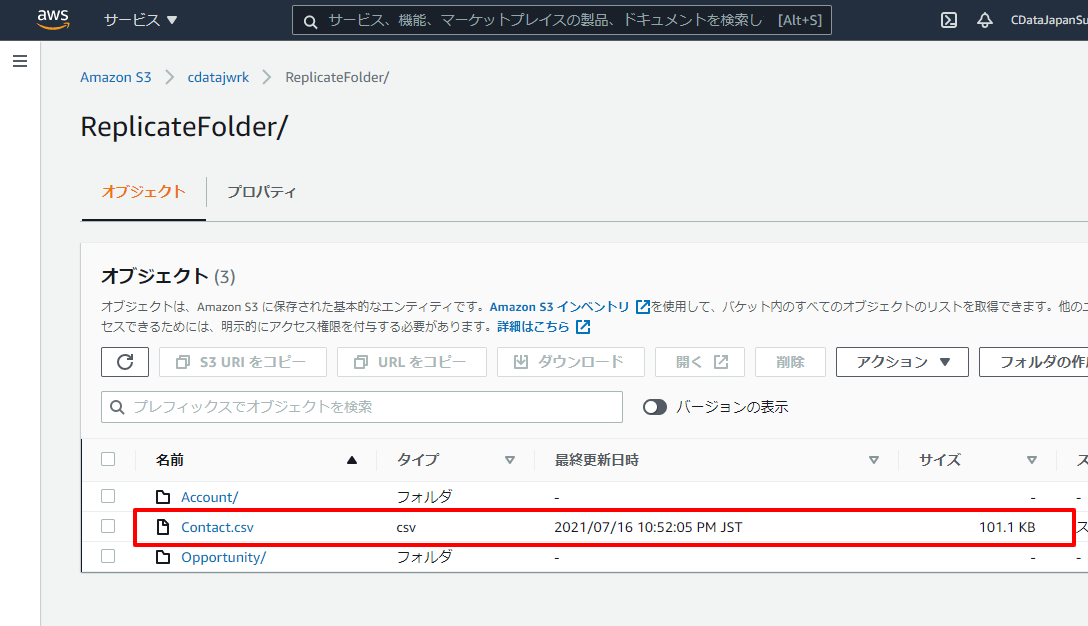
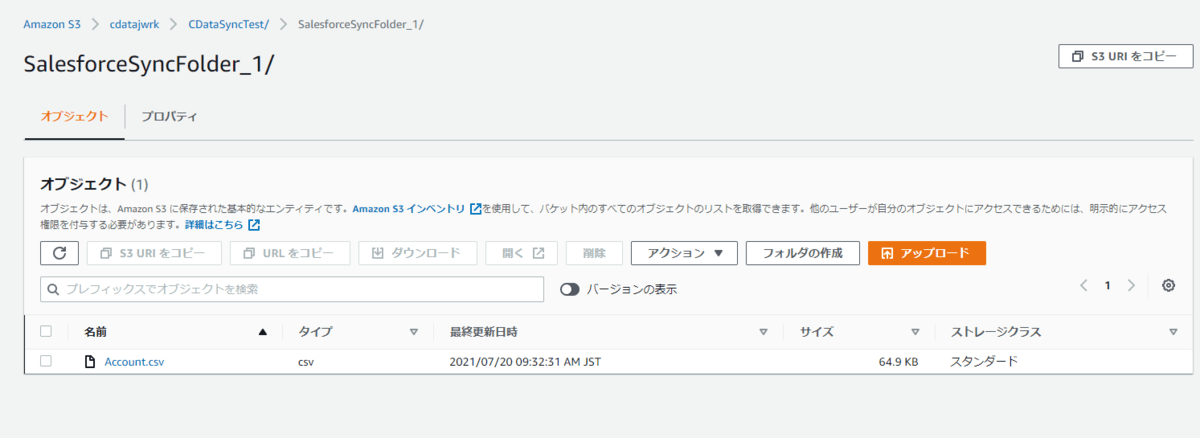
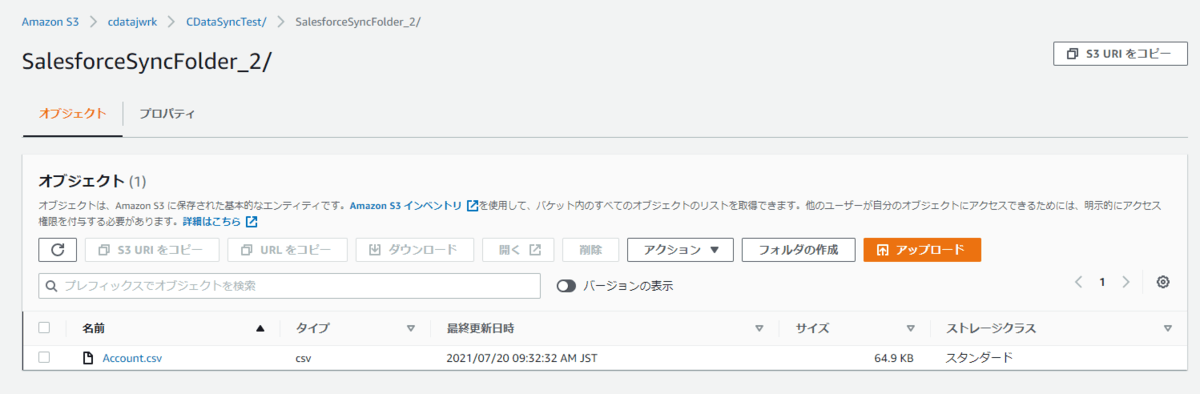
Amazon S3の対象フォルダを見てみると、それぞれのフォルダにCSVが出力されていることが確認できますね!
おわりに
このように単一の接続設定でも、Bucketのフォルダーを振り分けてデータの出力ができるようになっています。
予め最上位のBucketだけ指定しておけば、あとはジョブの中でかなり柔軟に出力することができますね。
その他何か気になる点があれば、お気軽にテクニカルサポートまで問い合わせてみてください!
https://www.cdata.com/jp/support/submit.aspx
関連コンテンツ



