こんにちは、CData Software Japan プロダクトチームの宮本です!
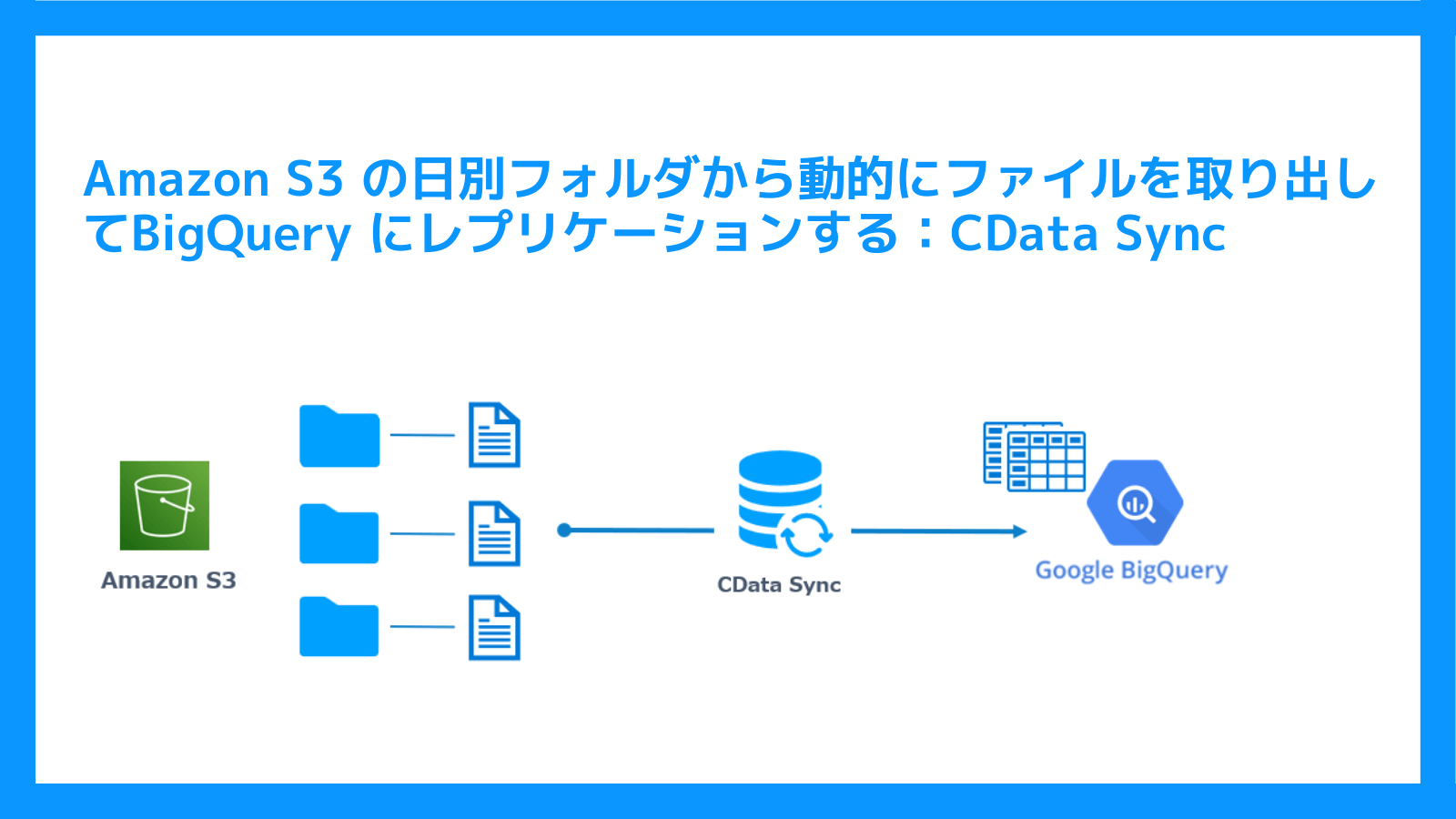
今回はデータパイプラインツールのCData Sync を使って、Amazon S3 に日別に作成されたフォルダに格納されているCSV ファイルの中身を動的に取得し、BigQuery に連携する方法をご紹介します。
CData Sync とは
国内/国外問わずさまざまなデータソースのデータを、指定のデータベースやデータウェアハウス、クラウドストレージに定期的にレプリケーションできるデータパイプラインツールです。
CData Sync 自体はセルフホスティング型のツールのため、ローカルマシンやクラウド上のVMインスタンス上、コンテナ上 でもご利用いただけます。
30日間の無償トライアルが可能ですので、まずはお試しされたい方はこちらからダウンロードができます。
CData Sync | ノーコードデータレプリケーション / ETL ツール
ではさっそく実現方法をみていきましょう。
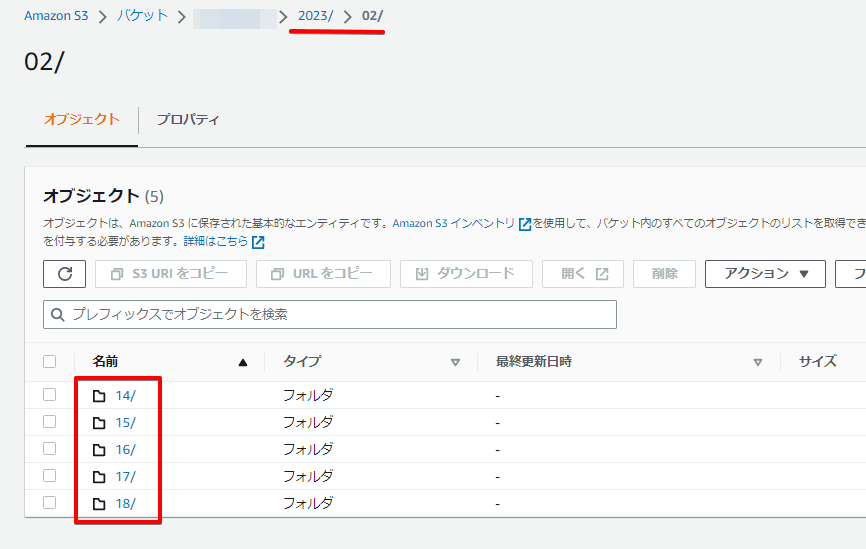
Amazon S3 の構成
バケット配下がyyyy → MM → dd の階層でフォルダが作成されています。
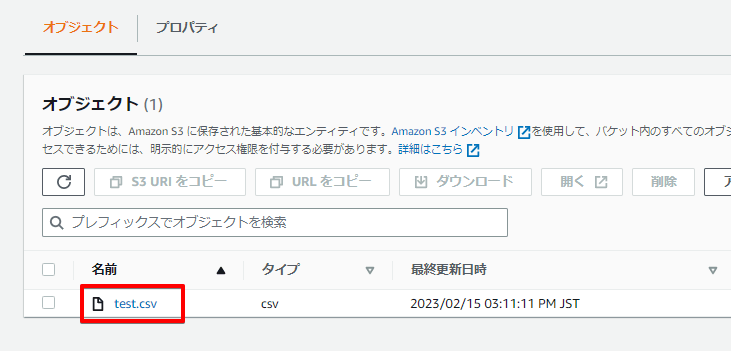
それぞれの日付フォルダの配下には「test.csv」が格納されています。
中身は適当なデータですが、日付フォルダと同日の日付がUpdatedAtで使用されています。
以下は18フォルダ配下のtest.csv ファイルの中身です。
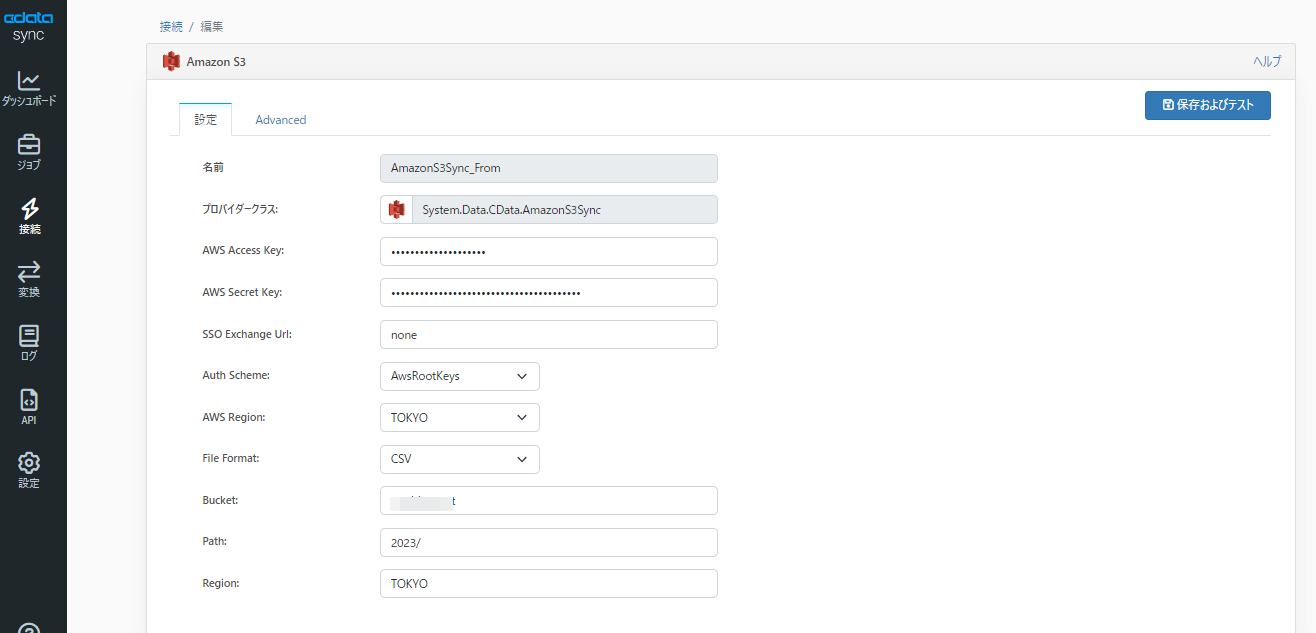
CData Sync の接続設定
まずはAmazon S3 への接続設定を行います。なお、今回は2023までは一旦固定にしたく、Path の値を2023/ に設定しています。
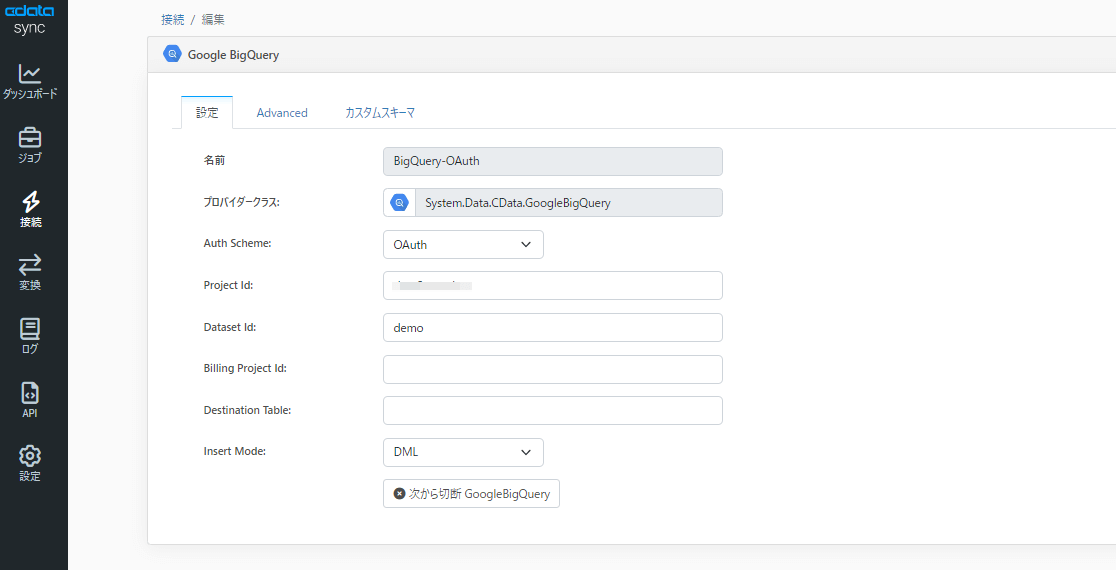
接続テストが完了したら次はBigQuery の接続設定を行います。接続方式はOAuth認証に加え、サービスアカウントでも可能ですが、今回はOAuth認証を使用していきます。
プロジェクトIDとデータセットIDを指定したら接続テストを行い、成功しましたら保存します。
※プロジェクトID、データセットIDは必須ではありません
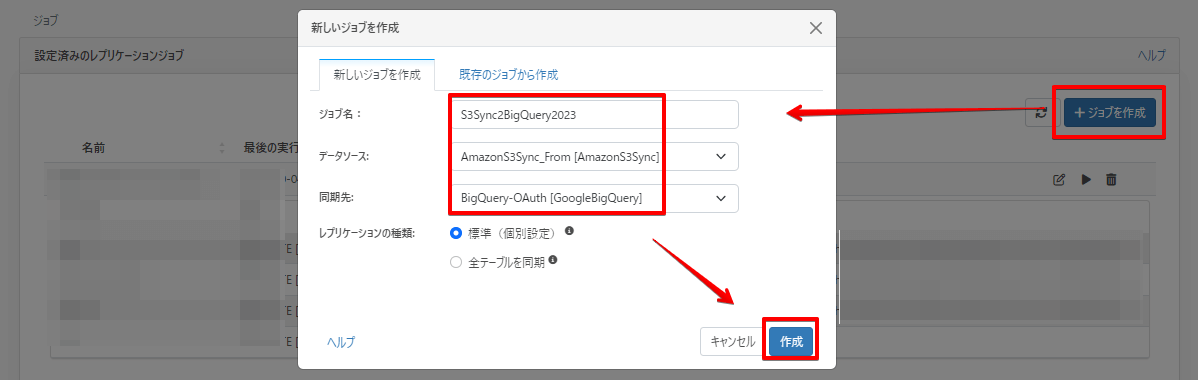
CData Sync ジョブ設定
まずはジョブの枠を作成します。ジョブ一覧画面 → ジョブを作成でデータソースにS3、同期先にBigQuery を指定して作成します。
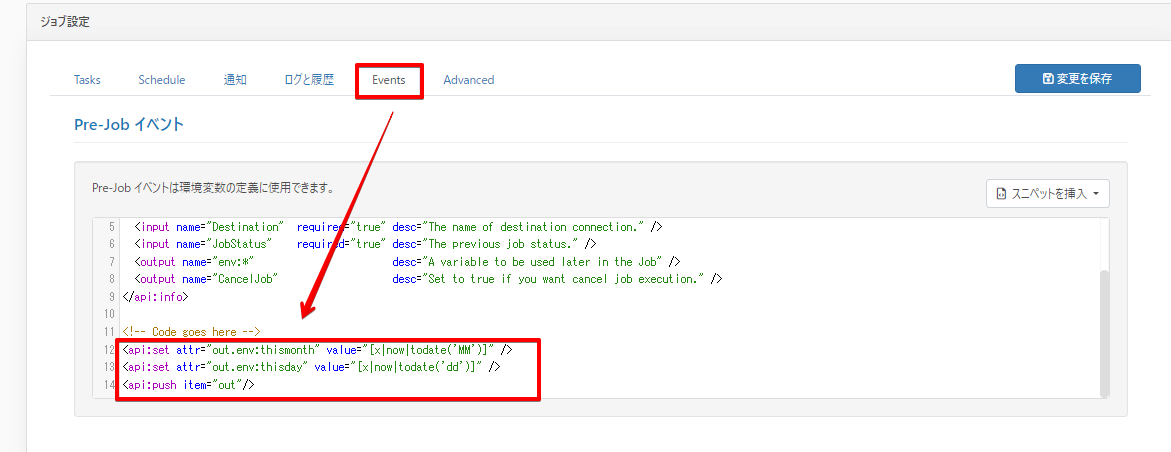
次はレプリケートクエリを作成していくのですが、日々動的にS3のパスを日付ごとに変更する必要があるので、
EventsタブのPre-Job にて変数にジョブ実行時の月日を取得してセットする処理を追加します。
※変数は「out.env:thismonth」と「out.env:thisday」になります。
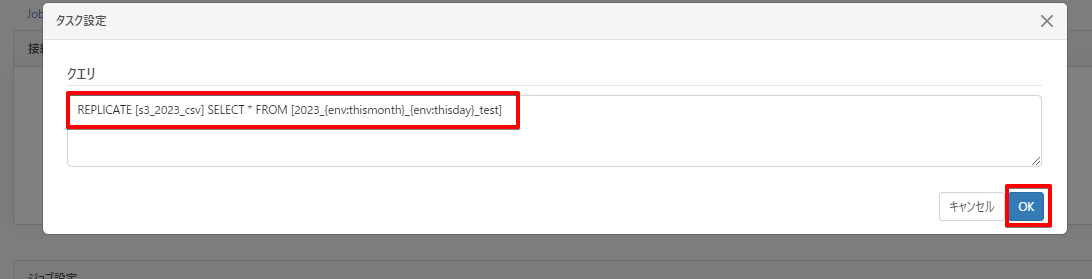
次に変数を加えたレプリケートクエリを作成します。
Tasksタブ →「カスタムクエリを追加」から、下記クエリを指定します。
REPLICATE [s3_2023_csv] SELECT * FROM [2023_{env:thismonth}_{env:thisday}_test]
ちなみに s3_2023_csv という名前は同期先テーブル名になりますので、任意の名前でご指定ください。
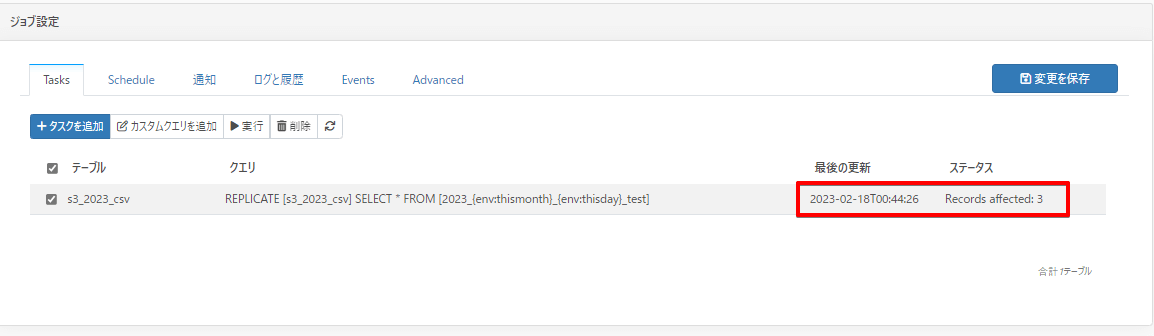
CData Sync ジョブ実行
現在日付が2023/02/18 の状態でジョブを実行してみると、このように3件BigQuery にレプリケーションできたという結果が返ってきました。
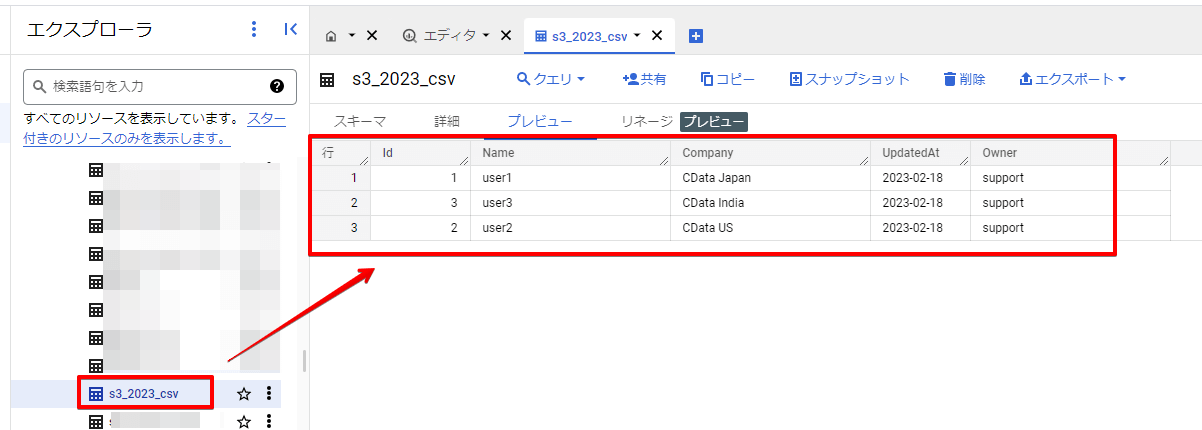
ちゃんとBigQuery に格納されていることが確認できました。
おわりに
いかがでしたでしょうか。Pre-JOBで環境変数を設定することで、動的に取得先のパスを変更することが可能になりました。
他にはテーブル名を実行日付で分けて運用するなども同じ方法で設定可能です。
今回ご紹介したCData Sync は30日間無償でトライアル利用ができますので、ぜひお試しください!
CData Sync | ノーコードデータレプリケーション / ETL ツール
関連コンテンツ



