はじめに
Glue Studioは、AWSの完全マネージド型ETLサービスをGUIからジョブを作成できる機能です。
docs.aws.amazon.com
CDataでは、GlueおよびGlue Studio にて、会計・CRM・ERP・MA・グループフェアなどの多種多様なSaaSやNoSQLデータベースからデータを抽出できるカスタムコネクタの提供を開始しました。
www.cdata.com
本記事では、Glue Studio、および、CData Glue Connectors製品を使ってSalesforceのデータを抽出してS3バケットに格納するジョブの作成方法をご紹介します。
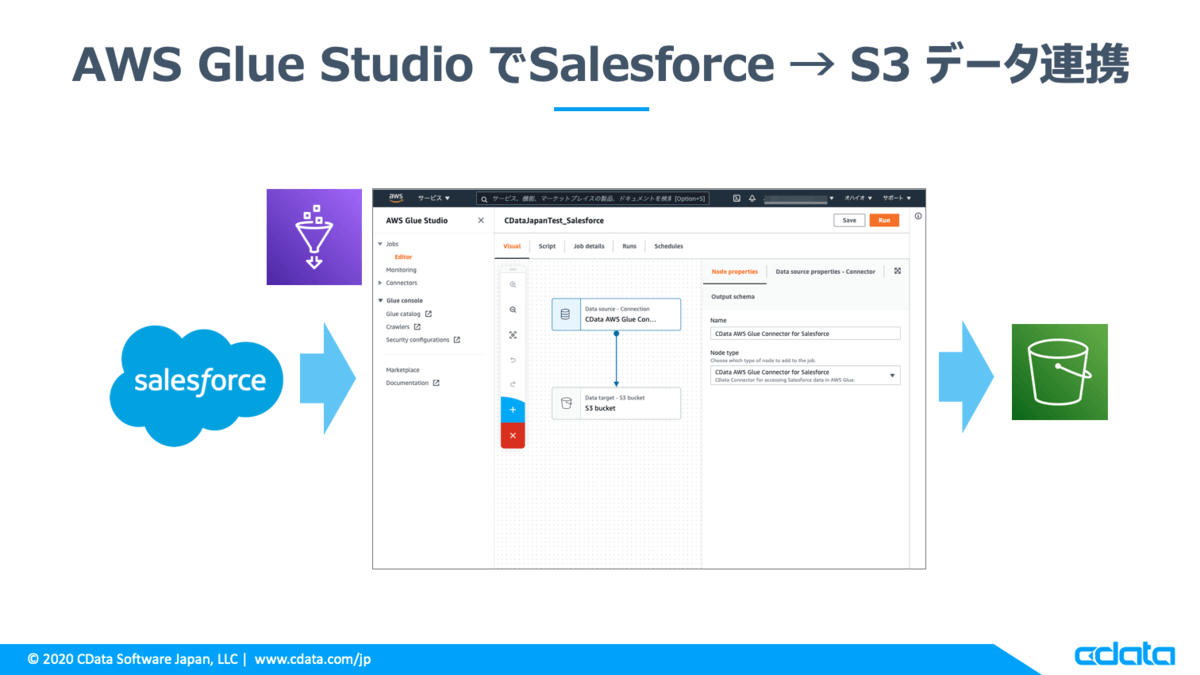
前提
- SalesforceのAPIアクセスできるアカウントを保有していること
- AWSのアカウントを保有していること
- AWS MarketplaceでCData Glue Connectors製品をサブスクライブ(購入)できること
手順
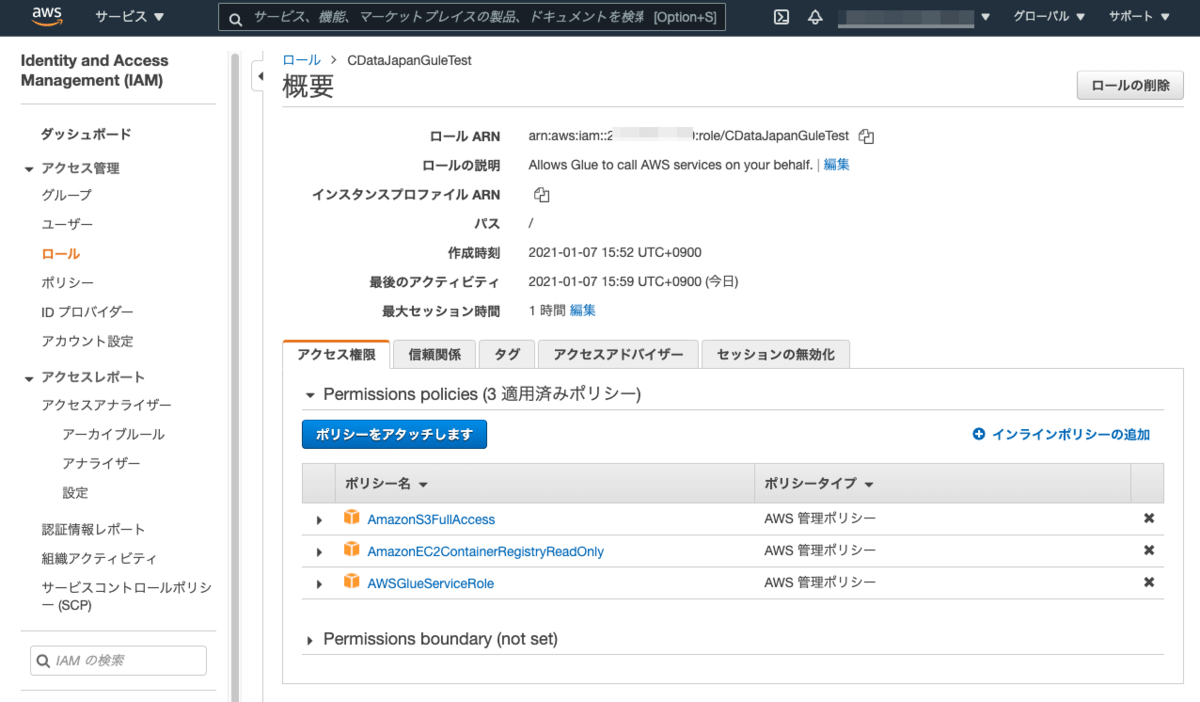
IAMロールの作成
Glueジョブを作成する時に以下のアクセス権限を保有するIAMロールが必要となります。
- AWSGlueServiceRole
- AmazonEC2ContainerRegistryReadOnly
- AmazonS3FullAccess
AWSマネジメントコンソールから「Identity and Access Management (IAM)」サービスを開いて上記アクセス権限を持つIAMロールを作成します。
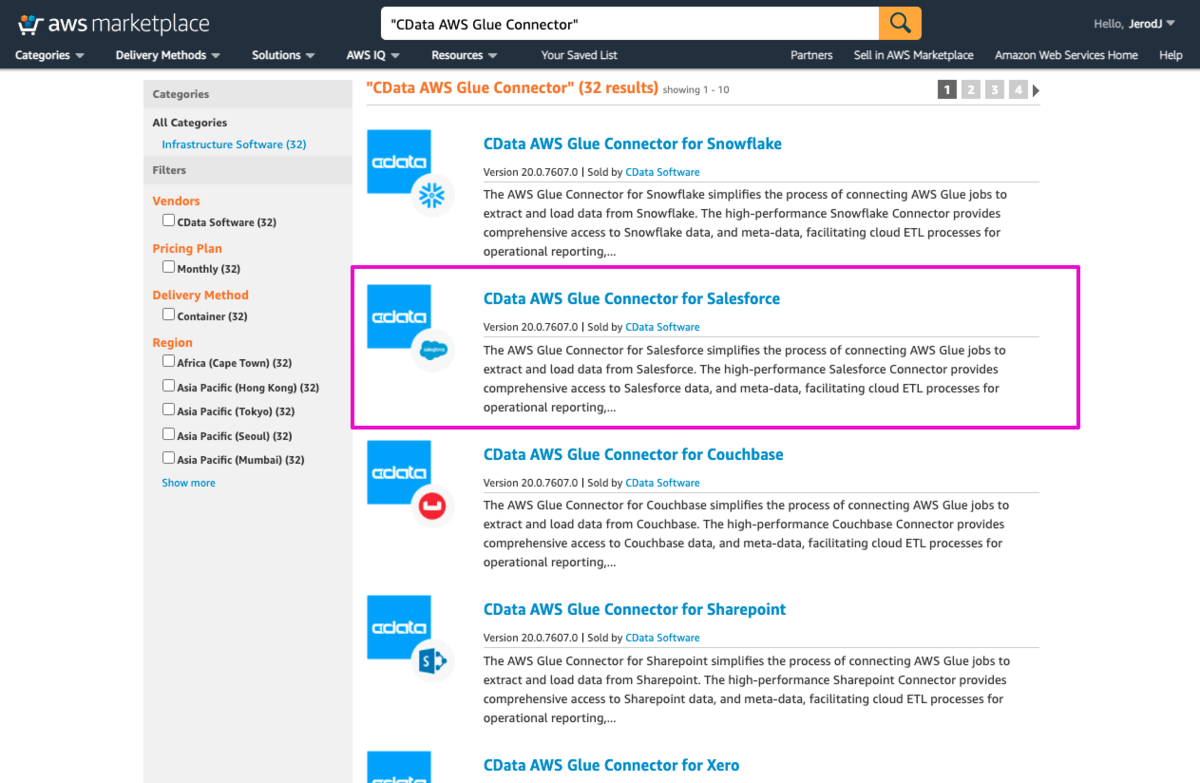
CData Glue Connector for Salesforceのサブスクライブ
こちらのリンクからAWS MarketPlaceにアクセスして、CData AWS Glue Connector for Salesforceを選択します。
Continue to Subscribeボタンをクリックします。
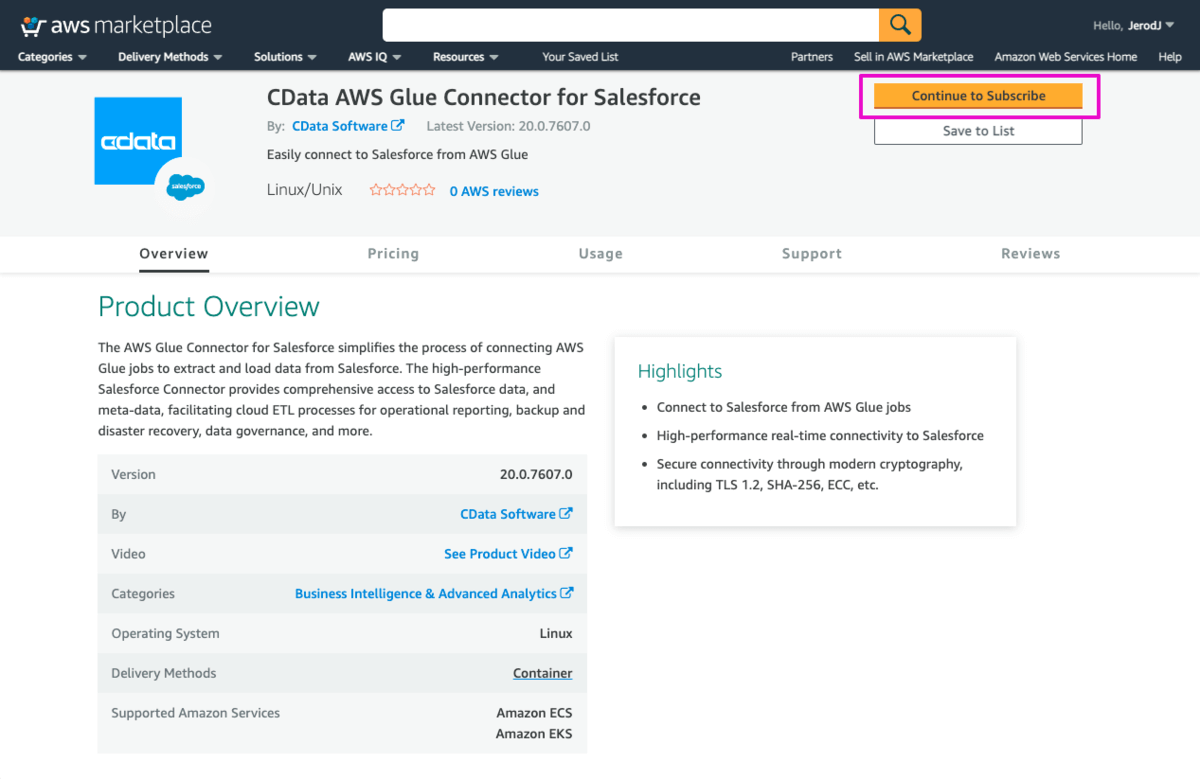
Termsを確認して、再度、活性化されたContinue to Subscribeボタンをクリックします。Continue to Configurationボタンをクリックします。 ※課金されますのでご注意ください
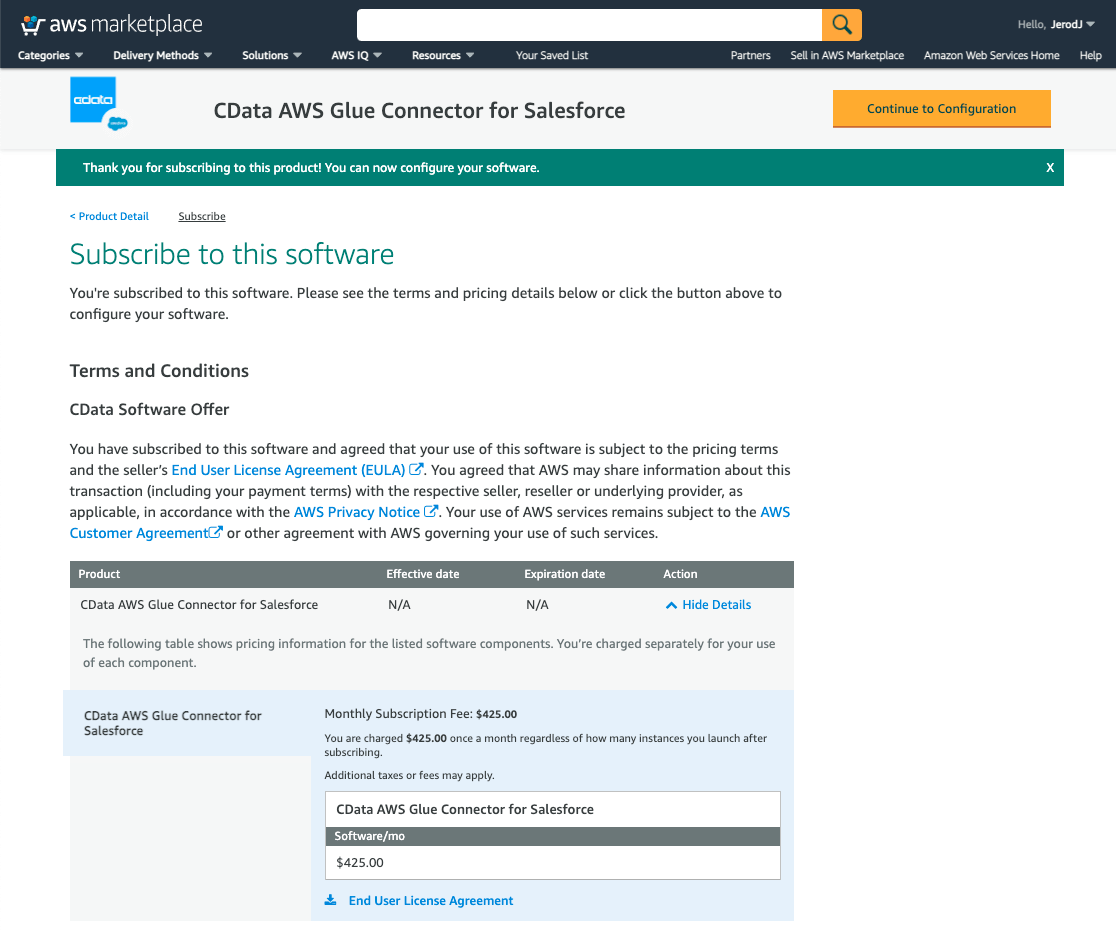
Configure this software画面が表示されるので、Delivery MethodにはCData AWS Glue Connector for Salesforceが、Software Versionに最新のものが選択されていることを確認して、Continue to Launchボタンをクリックします。
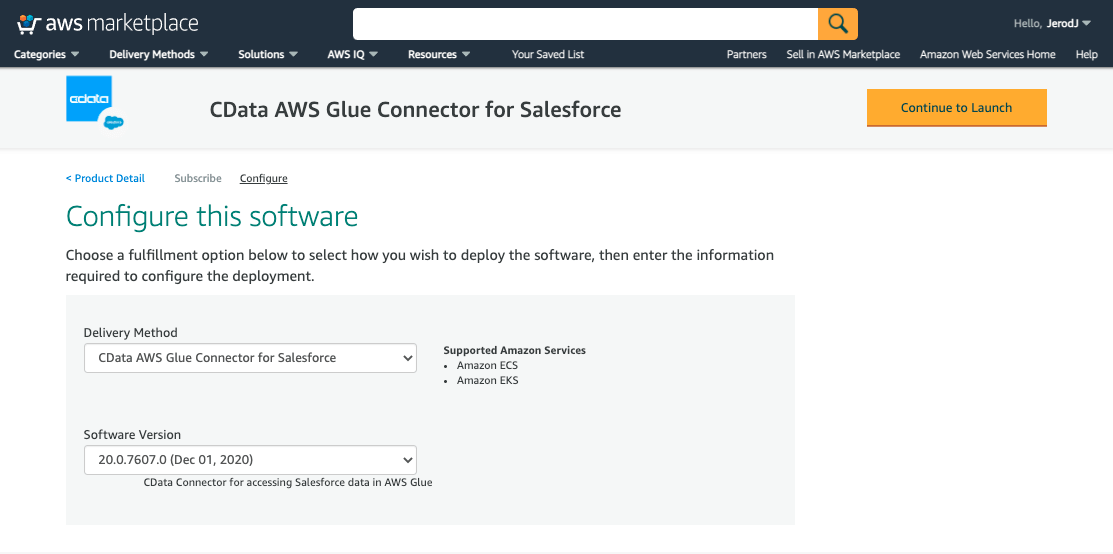
CData AWS Glue Connector for SalesforceがLaunchされたことを確認します。
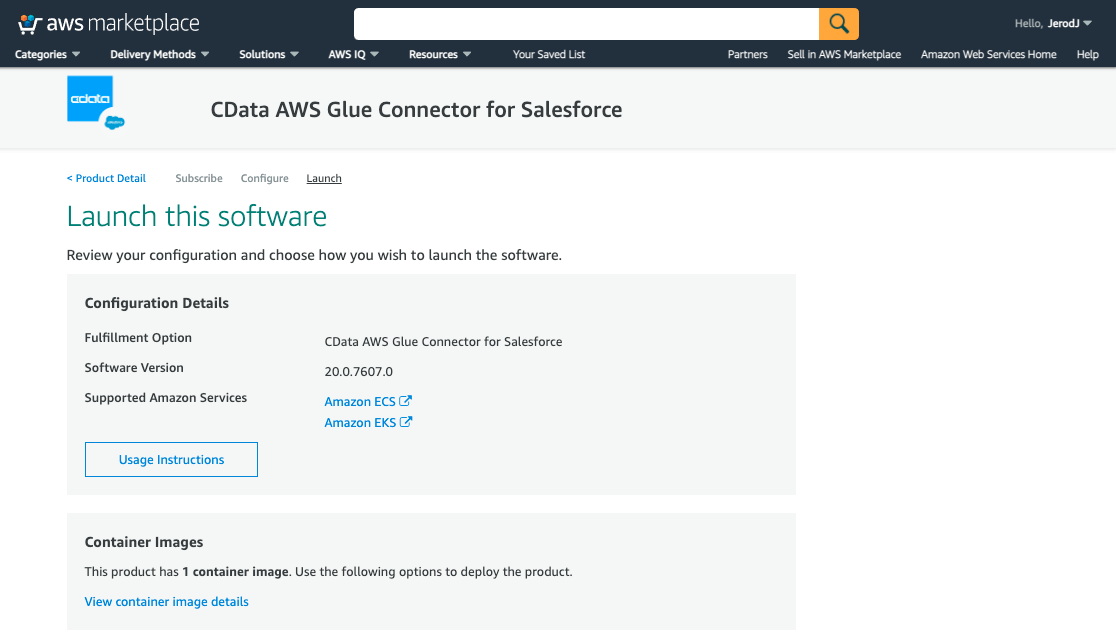
Usage Instructionsボタンをクリックして表示されるウィンドウ内の「Activate the connector with AWS Glue Studio」リンクを開きます。
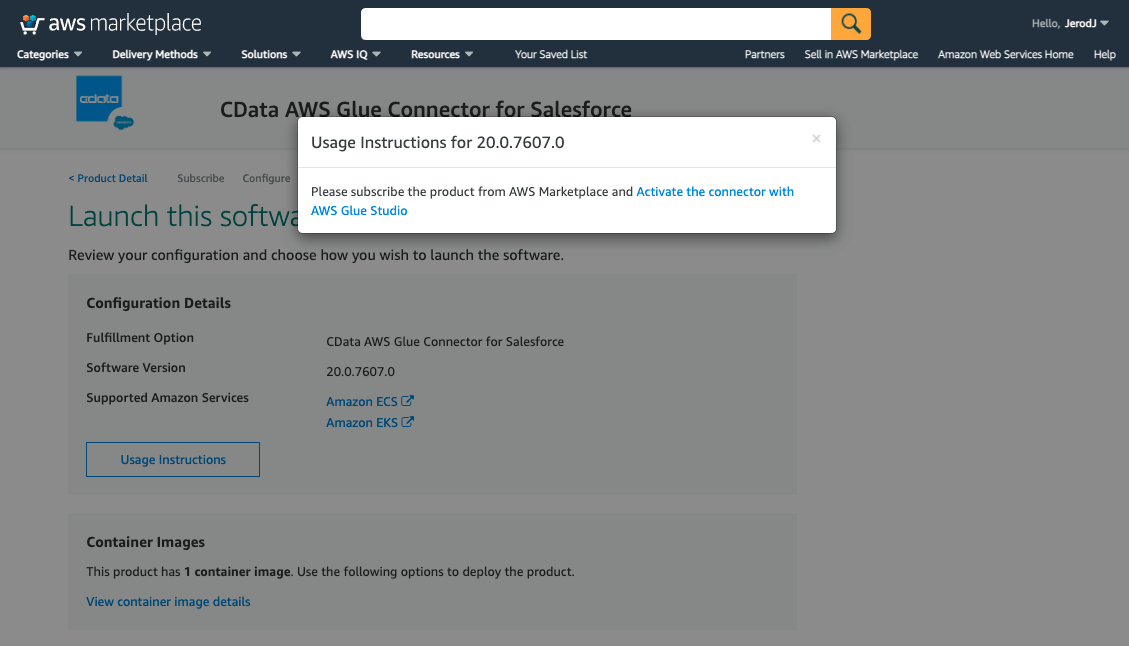
Create connection画面が開くので、Activate connector onlyをクリックします。これで、Glue StudioからCData Glue Connector for Salesforceが利用できるようになりました。
Connectionの作成
AWS Glue StudioのConnectors画面で、connectorsからCData Glue Connector for Salesforceを選択してCreate connectionを開きます。
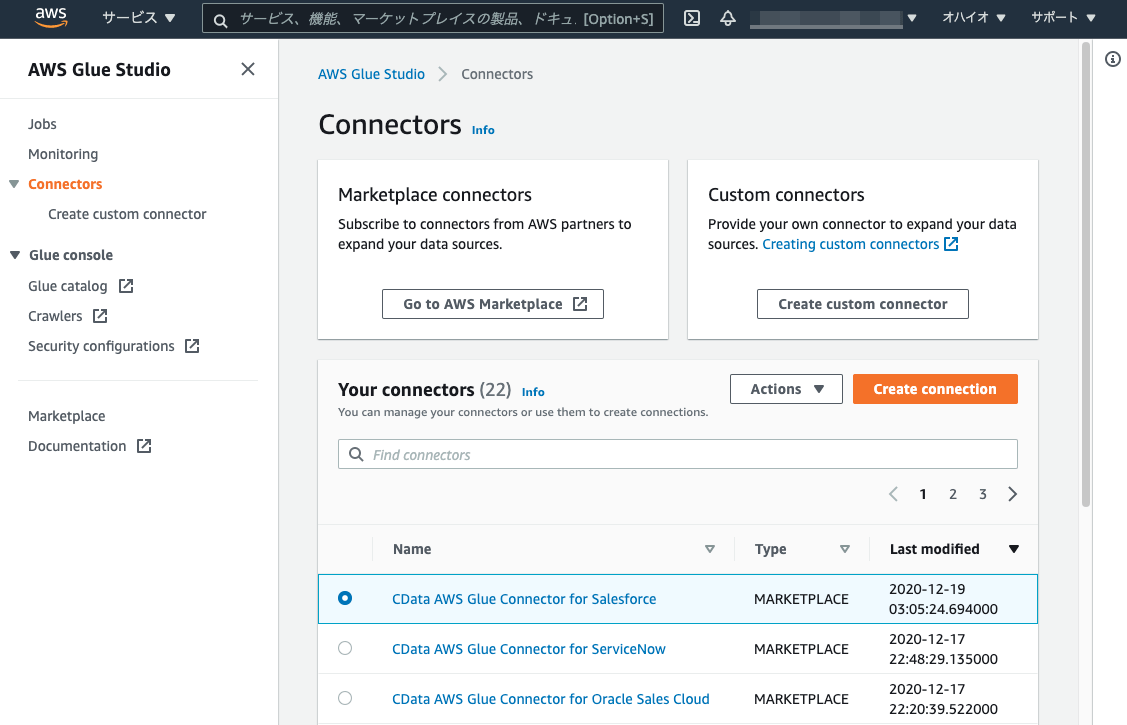
Create connection画面が開きます。Nameに任意の名称(本例では、Salesforce_Jp)をセットします。
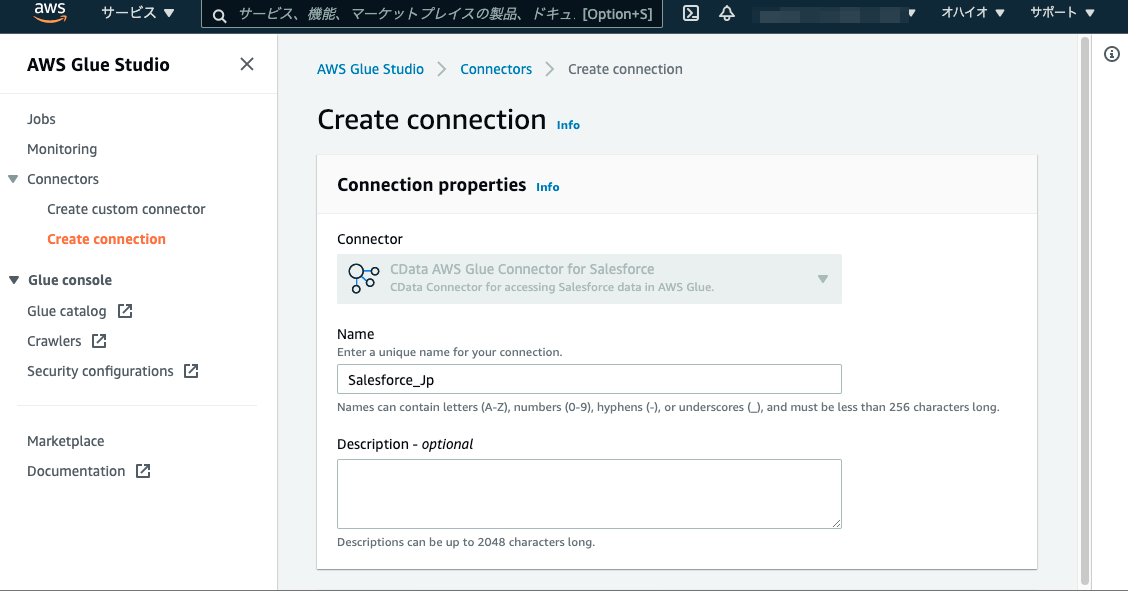
スクロールダウンして、Connection credential typeには「username_password」を選択します。
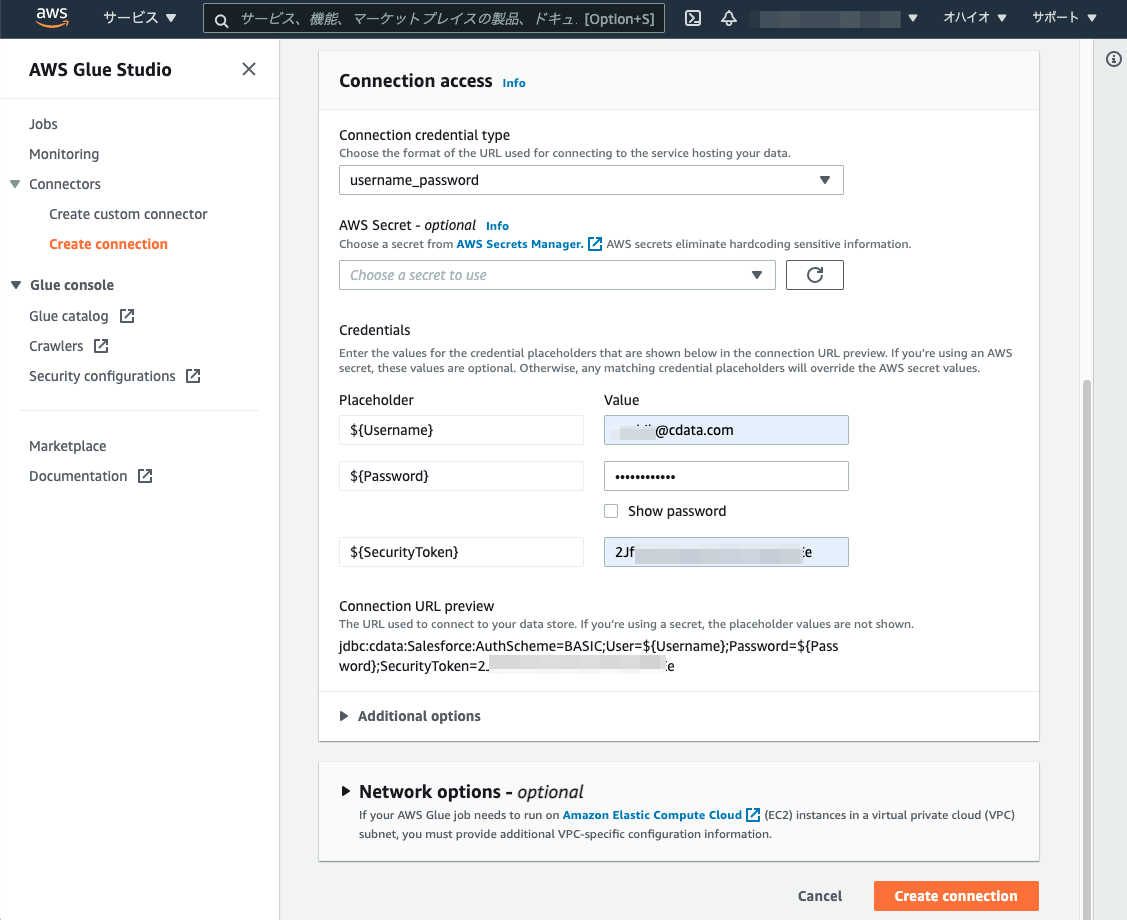
Credentialsには以下の値をセットします。
| Placeholder |
value |
| ${Username} |
Salesforceへのログインユーザー |
| ${Password} |
Salesforceへのログインパスワード |
| ${SecurityToken} |
Salesforceのセキュリティトークン |
※セキュリティトークンの取得方法はこちらの記事をご参照ください
Create connecitonボタンをクリックします。
Jobの作成
AWS Glue StudioのJobを開き、Create jobからBlank graphを選択してCreateボタンをクリックします。
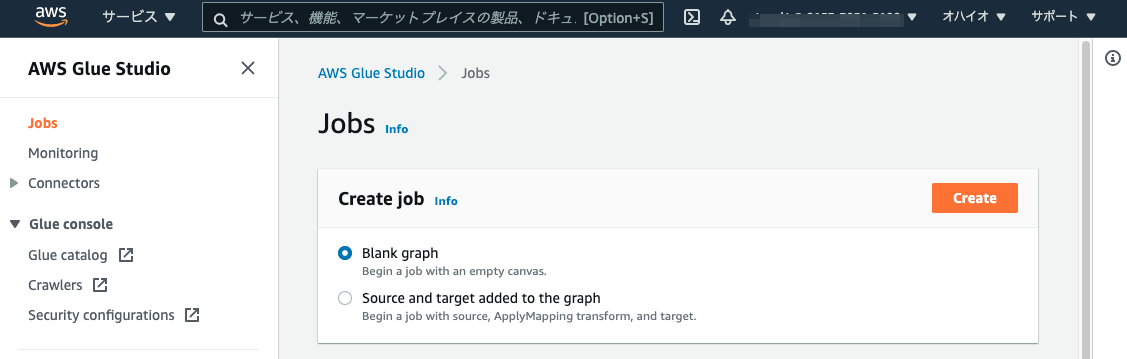
Visualキャンバス上の青のプラスボタンをクリックしてNodeを追加します。追加したNodeのNode propertiesタブにてNameに任意の名称(本例では、Salesforce)をセットしてNode typeにはCData AWS Glue Connector for Salesforceを選択します。
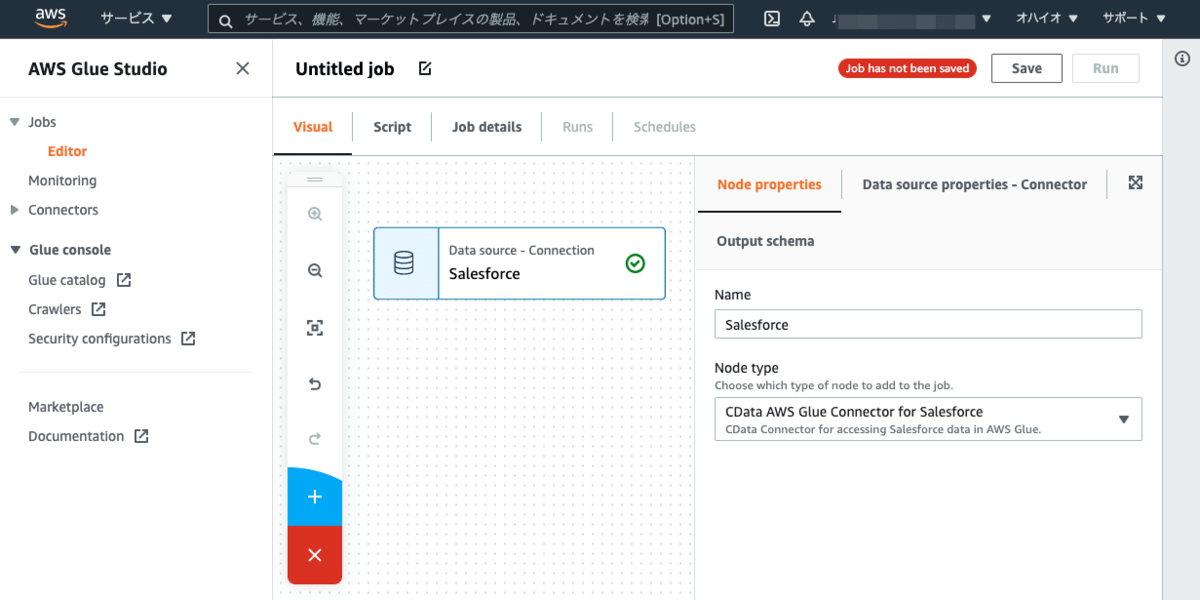
続いてData source properties - Connectorタブを開きます。Connectionには前の手順で作成したConnection(例:Salesforce_Jp)を選択します。今回の手順では、Lead(見込み客)のデータを全件取得するため、Enter table nameを選択してTable nameにはLeadをセットします。
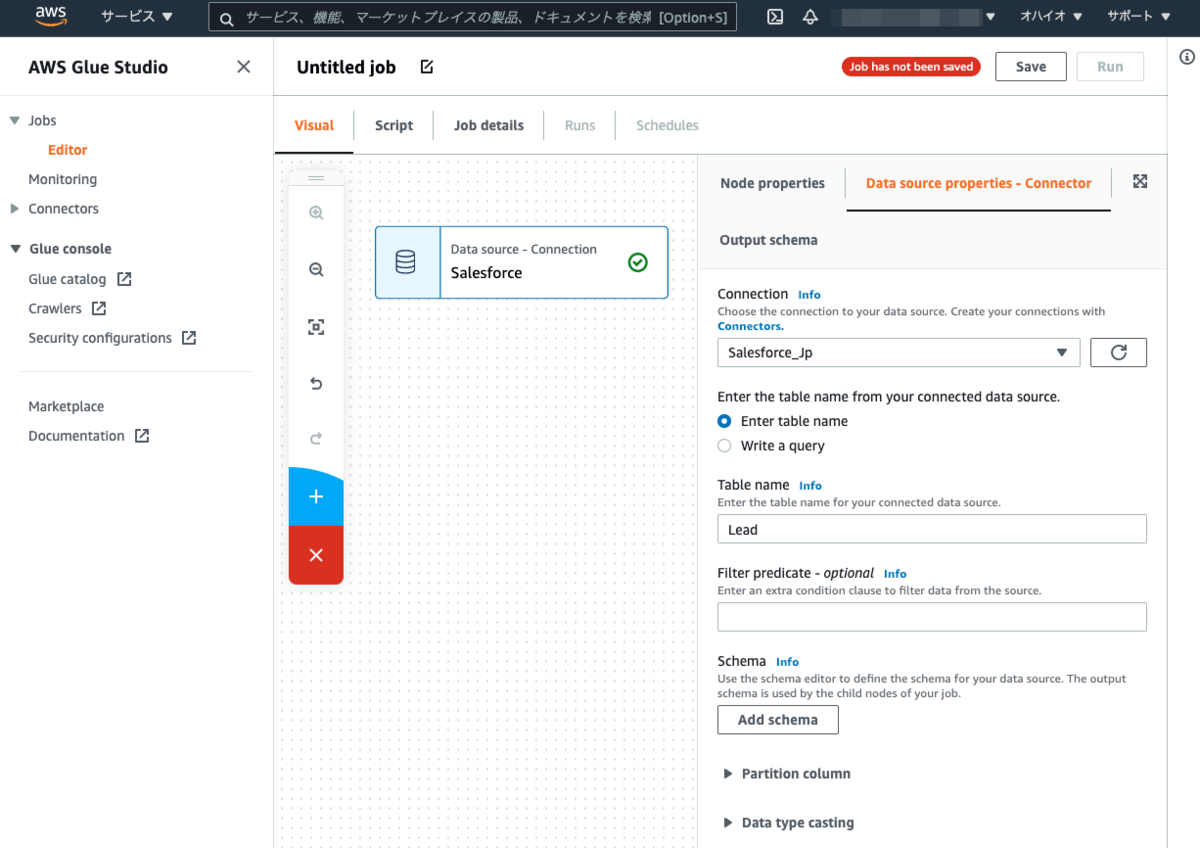
再度、Visualキャンバス上の青のプラスボタンをクリックしてNodeを追加します。Node propertiesタブのNameには任意の名称(本例では、S3)をセットして、Node typeはData target内のS3を選択します。Node parentsは先の手順で作成したSalesforceからの抽出Node(Salesforce)です。
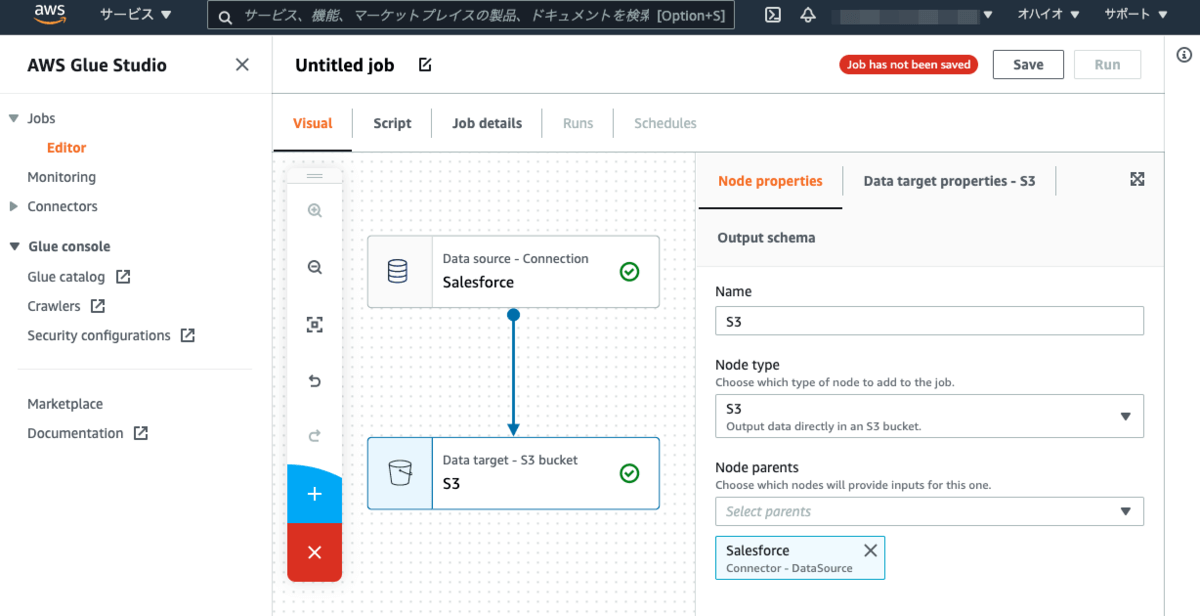
Data target properties -S3タブを開きます。FormatはJSON、Compression TypeはNone(圧縮しない)、S3 Target Locationには、出力先のS3バケットをセットします。
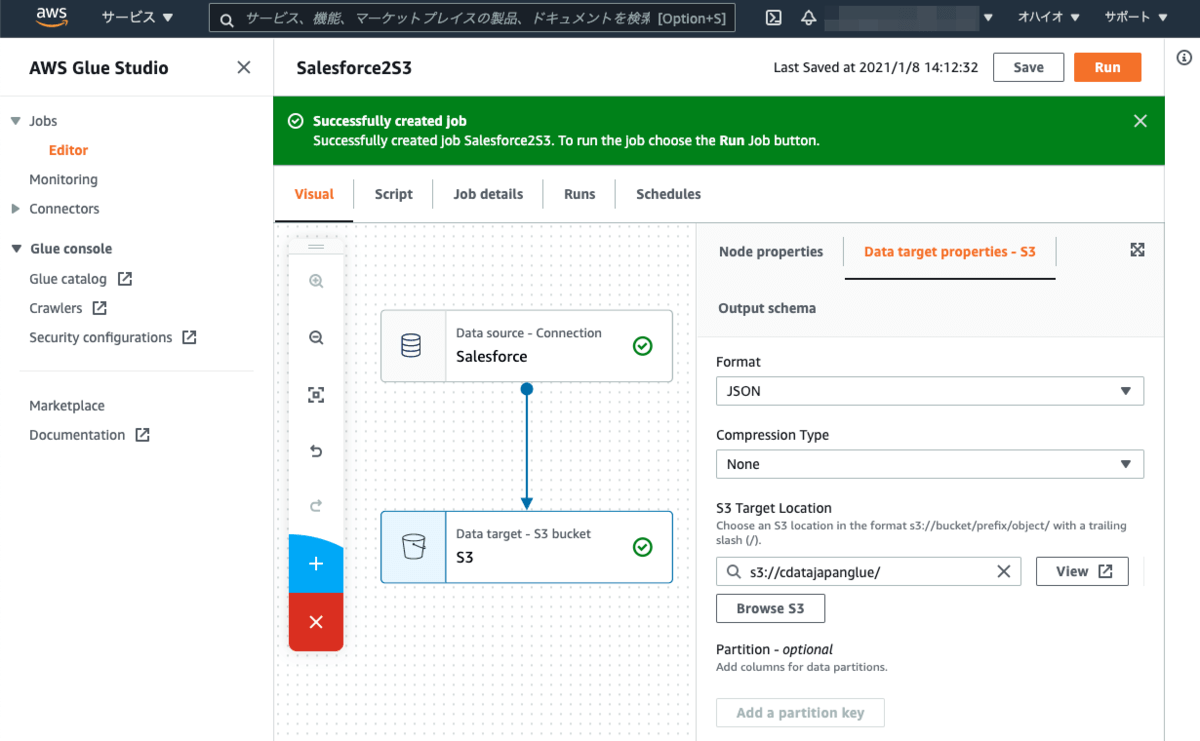
続いて、Job detailsタブを開きます。Nameにジョブの名称(本例では、Salesforce2S3)をセットして、IAM Roleは先の手順で作成したIAMロールを選択します。他の項目はデフォルトのままで構いません。SaveボタンをクリックしてJobを保存します。
Jobの実行
それでは、作成したJobを実行(Run)してみましょう。右上のRunボタンをクリックします。
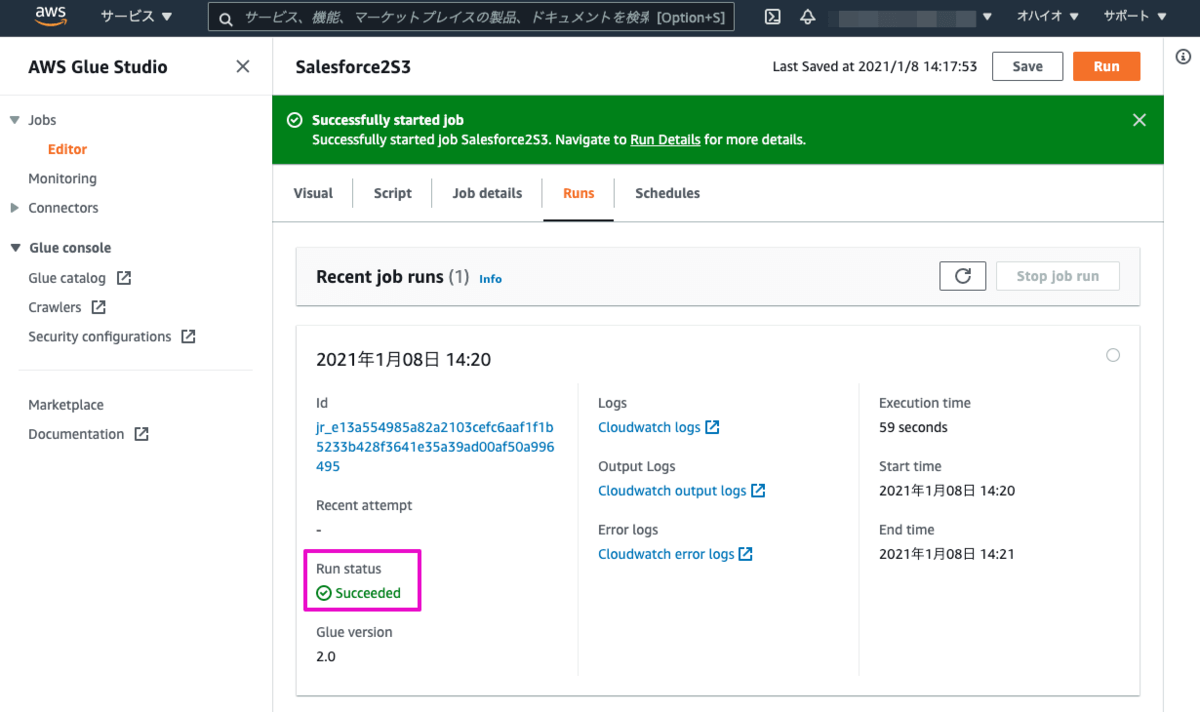
Runsタブを開きジョブの実行状況を確認します。ジョブが終了してRun statusがSucceededが表示されれば成功です。失敗した場合は本画面からLogを確認することが出来ます。
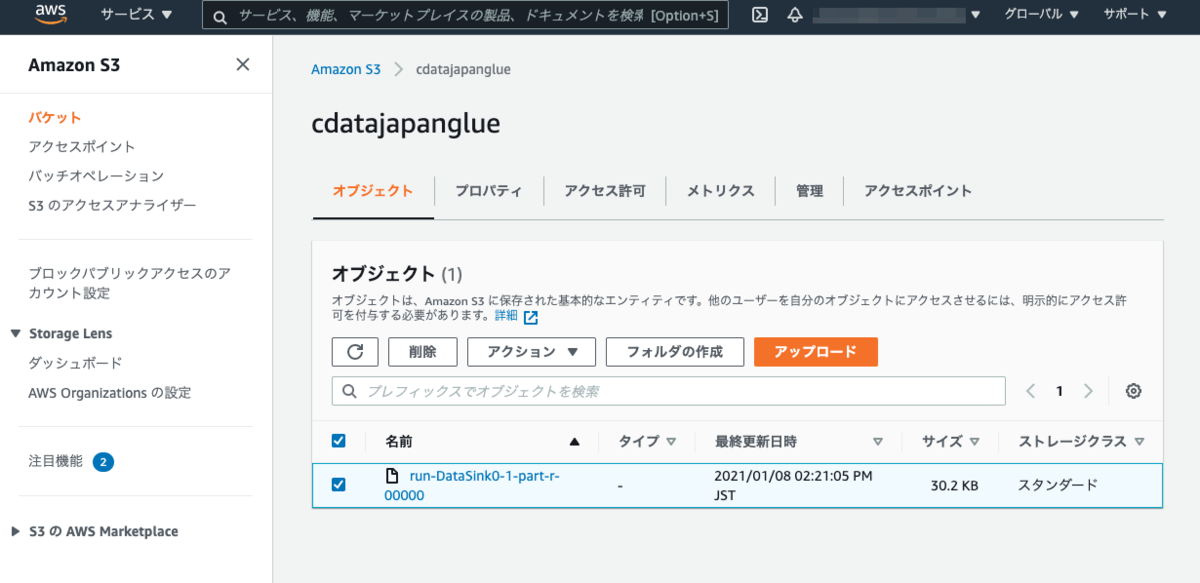
S3へ連携されたデータの確認
上記Jobで出力先として設定したS3のバケットを開きます。バケット内にオブジェクトが追加されていることを確認します。
追加されたオブジェクトのデータをS3 Selectを使用したクエリで参照します。
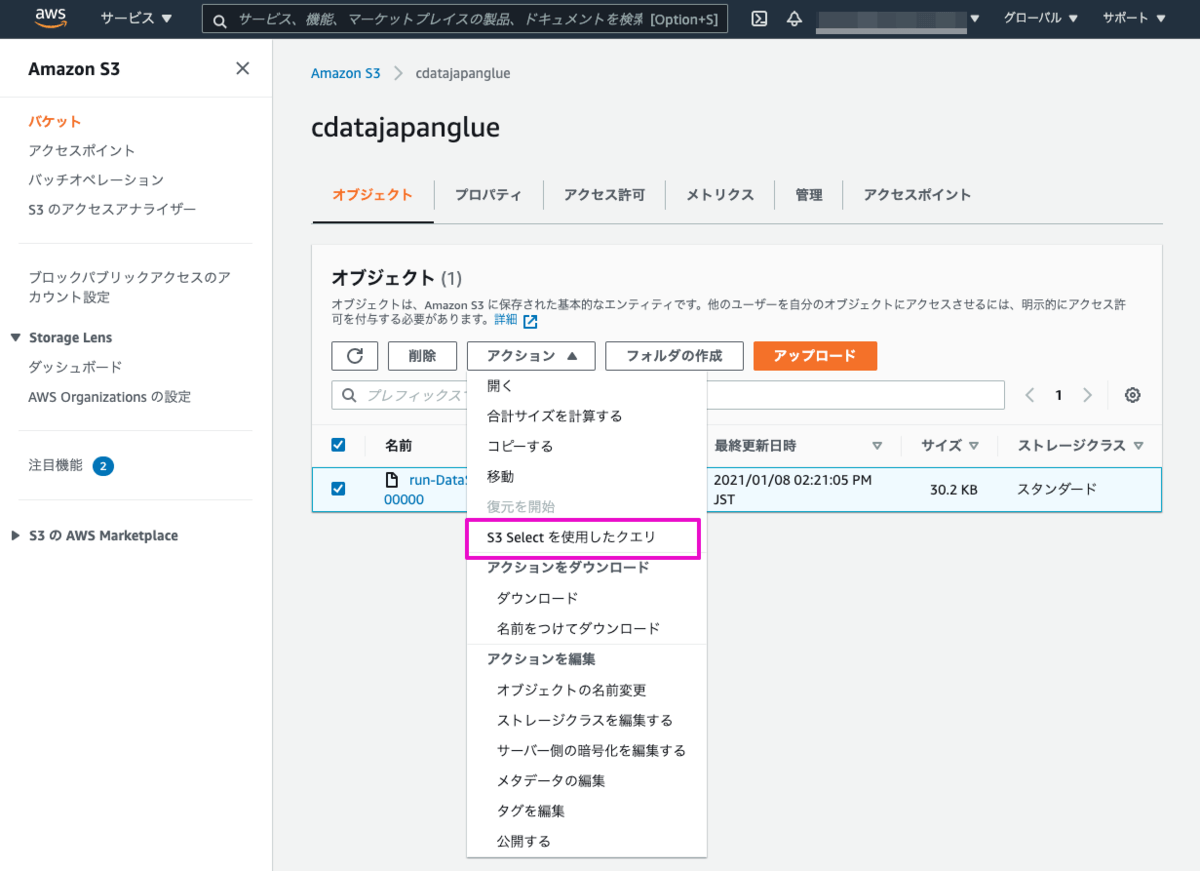
ジョブのTargetNode(S3)で形式をJSONに選択したので、入力設定の形式もJSONに合わせます。
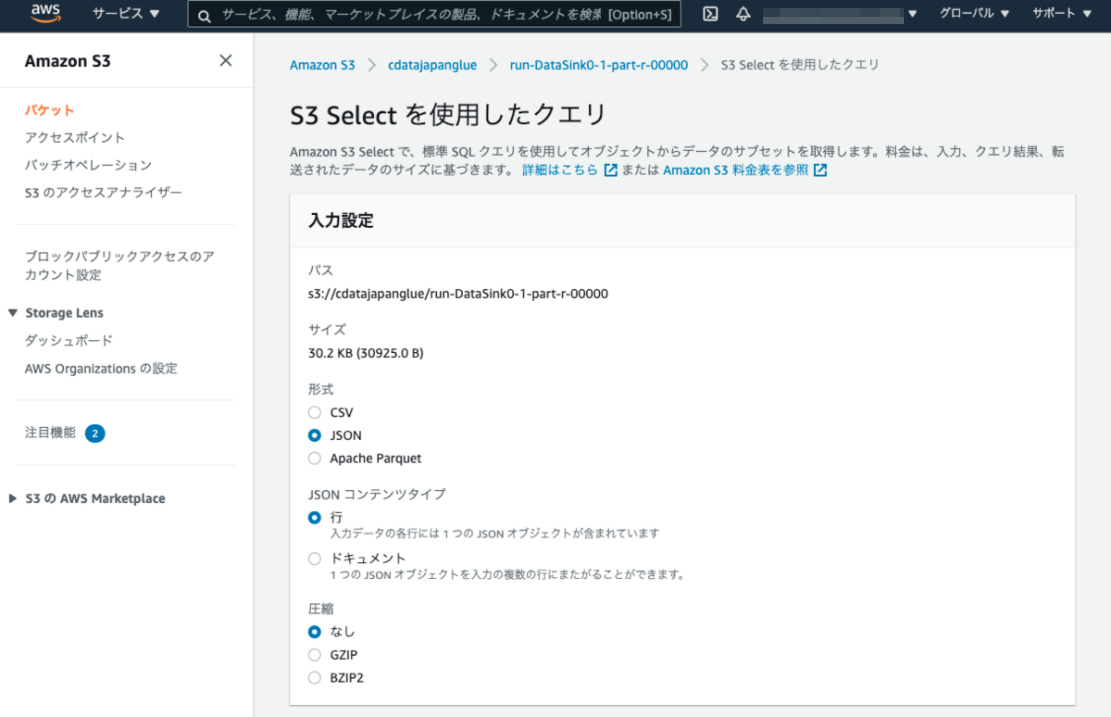
以下のSQLクエリを実行します。
SELECT * FROM s3object s LIMIT 5
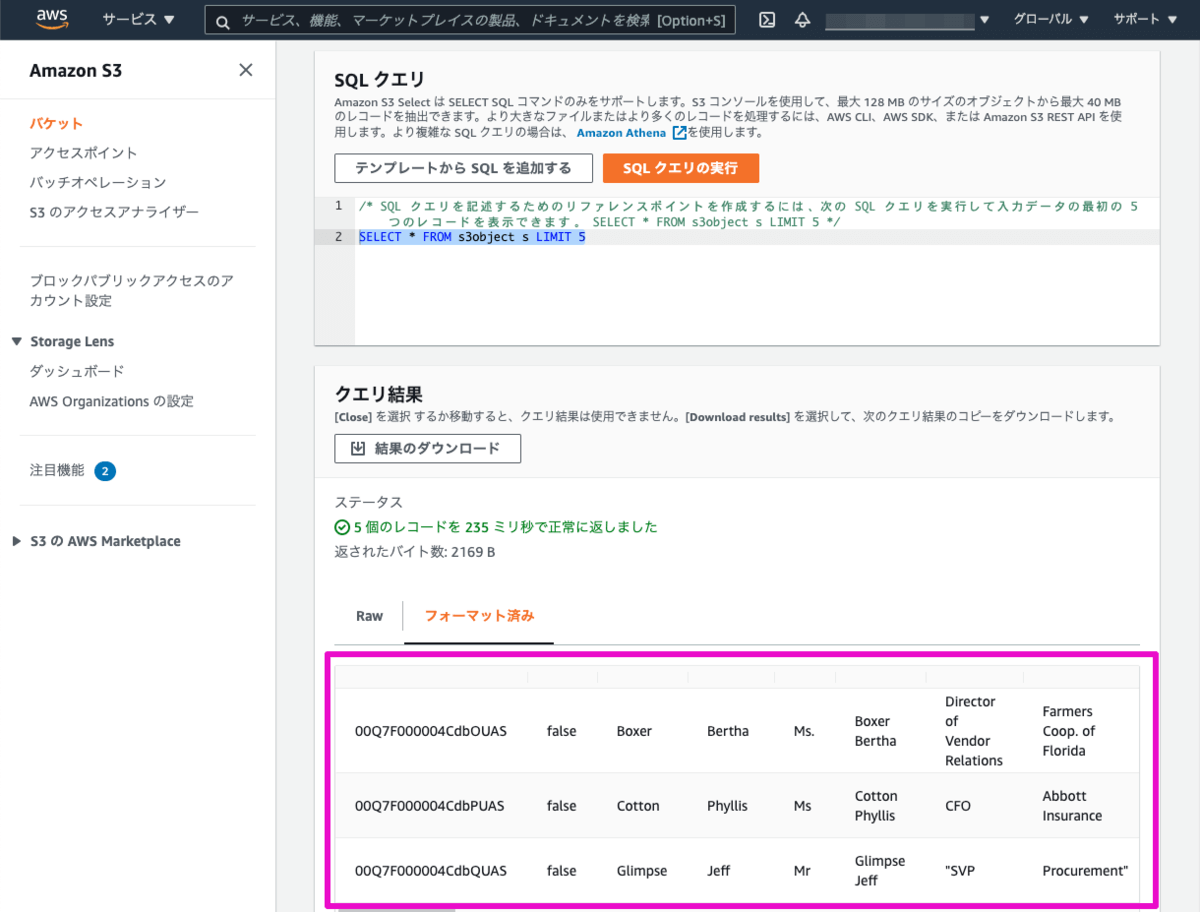
クエリ結果でフォーマット済みを選択して、SalesforceのLead(見込み客)のデータが抽出出来ていることを確認します。
まとめ
本記事では、SalesforceのLead(見込み客)の抽出を例にご紹介しましたが、Salesforce内の他オブジェクト(AccountやOpportunityなど)や、本サイトの様々なデータソース(Hubspot、Netsuite、MongoDB、Snowflakeなど)からの抽出も同様の手順で可能です。

是非、GlueおよびGlueStudioを利用してデータレイクを構築している方はご活用ください。
関連コンテンツ



