「リード(Lead)」とは「見込み客」を指すマーケティング用語です。 例えば既存顧客からの紹介、Webサイトからの問い合わせ、展示会やイベントでの名刺交換などで連絡先を入手した人など、今後の取引を期待する相手がリードに相当します。 企業では獲得したリードを営業でフォローし、取引につなげることを目指して活動しますが、限られた営業リソースを効率的に使うためには期待値の高いリードを選別して集中的にリソースを投入することが重要です。
Salesforceでは個々のリードに対して連絡先や評価、コンタクトの履歴など詳細な情報を記録し追跡することができます。 今回はSalesforceのリードデータを分析し、個々のリードの特徴からそれらが取引につながるかどうかを予測します。
リードの予測には機械学習を用います。 今回は処理の実装言語としてPythonを使い、機械学習のライブラリにScikit-learnを利用しました。
シナリオ
各リードの特徴からそのリードが取引につながるかどうかを予測します。
学習と予測の流れは下図の通りです。 予測モデルは既にクローズしたリードをもとに構築し、そのモデルを使ってまだクローズしていないリードの結果を予測します。

リードがクローズしたかどうかの判別には「リード状況」フィールドを見ます。 リード状況が「Closed」のものをクローズしたリードとみなします。

今回は予測を格納する「結果予測 (PredictedStatus__c)」というカスタムフィールドを作成しました。 予測が実行されると、クローズしていないレコードの結果予測フィールドに以下二つの結果のいずれかが入ります。
- Likely converted : 取引につながる可能性が高い
- Not likely converted : 取引につながる可能性は低い
学習モデル
今回の課題は「教師あり」の「分類課題」に区分けされます。 適当なアルゴリズムとしてはk-近傍法やSVM、決定木などがありますが今回はロジスティック回帰を使います。
用いた特徴量と目的変数は以下の通りです。
特徴量
| 項目名 |
説明 |
| LeadSource |
リードソース |
| Industory |
業種 |
| AnnualRevenue |
年間売上高 |
| NumberOfEmployees |
従業員数 |
| Rating |
案件の評価 |
目的変数
| 項目名 |
説明 |
| Status |
取引へ変換されたかどうか |
本記事ではデータの取得から予測までの一連の流れを紹介することを目的としており、高精度のモデル構築は目指しません。 実用化にはアルゴリズムや特徴量の選択、ハイパーパラメータのチューニングに時間をかけてモデルの精度を高める必要があります。
データへのアクセス方法
Web APIを介してSalesforceのリードデータにアクセスし、データ分析をPythonで行います。 しかし、PythonからSalesforceのWeb APIを直接叩くためにはAPI仕様や認証プロセスなど多くのことを理解し実装しなければなりません。 そこで今回はCData Software Japan社のCData Salesforce Python Connectorを利用します。 Python Connectorsは様々なクラウドサービスのデータを標準のPythonデータベース接続でアクセス可能にするドライバです。 データの取得、挿入、更新、削除操作をSQLで記述することができます。

モデルの構築と予測
CData Python Connectorのインストール
CData Software Japan社のSalesforce Python Connectorダウンロードページにアクセスしてください。 ダウンロードページの「ベータ版ダウンロード」をクリックすると必要事項入力画面が表示されます。

必要事項を入力し、「ダウンロード」をクリックするとSalesforce Python Connectorベータ版がダウンロードされます。 ダウンロードされたファイルを展開して「CData.Python.Salesforce」フォルダからインストール対象のOSのフォルダに移動し、その下のPythonバージョンのフォルダに移動してください。 対象のフォルダに移動したら"pip install"コマンドでwhlファイルをインストールしてください。
例えば、WindowsマシンでPython 3.7 64bitバージョンを利用している場合、以下のようにコマンドを実行します。
>cd ./CData.Python.Salesforce/win/Python37/64
>pip install cdata_salesforce_connector-19.0.7416-cp37-cp37m-win_amd64.whl
これでインストールは完了です。 "pip list"コマンドを実行し、"cdata-salesforce-connector"が表示されていれば成功です。
> pip list
Package Version
-------------------------- ---------
cdata-salesforce-connector 19.0.7416
コード
それではモデルの構築から予測結果の出力まで実際のコードを用いて説明します。
ライブラリのImport
必要なライブラリをimportします。 numpy, pandas, sklearnがインストールされていない場合は"pip install"でそれぞれインストールしてください。
import cdata.salesforce as mod
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
Salesforce からデータを取得
Salesforce へアクセスするための認証情報を接続文字列の中に記述します。 ユーザ名、パスワード、セキュリティトークンをそれぞれ設定してください。
CONNECTION_STRING = "User=<ユーザ名>;Password=<パスワード>;SecurityToken=<セキュリティトークン>;"
データを取得するSQL 文を作成します。 特徴量、目的変数の他に、予測結果のデータを更新するために各レコードを識別するIdを取得します。
sql = "SELECT Id, LeadSource, Status, Industry, Rating, AnnualRevenue, NumberOfEmployees FROM Lead WHERE Country='Japan'"
columns = ['Id','LeadSource','Status','Industry','Rating','AnnualRevenue','NumberOfEmployees']
作成したSQL を使ってSalesforce からデータを取得します。 Pandasのread_sql_query()は指定されたSQL でデータベースにクエリを発行し、取得したデータをDataframeとして返します。 返されたDataframeに列名のセットを付与します。
conn = mod.connect(CONNECTION_STRING)
df = pd.read_sql_query(sql, conn)
conn.close()
df.columns = columns
データクレンジング
リードデータにはカテゴリ変数が含まれているため、これらを数値化します。
df['Status'] = df['Status'].map( {'Closed - Converted': 1, 'Closed - NotConverted': 0, 'Working - Contacted': -1} ).astype(int)
df['Rating'] = df['Rating'].map( {'Hot': 1, 'Warm': 0.5, 'Cold': 0} ).astype(int)
lead_source = pd.get_dummies(df["LeadSource"], drop_first=True, prefix="LeadSource")
industory = pd.get_dummies(df["Industry"], drop_first=True, prefix="Industry")
df = pd.concat([df, lead_source,industory], axis=1)
df.drop(['LeadSource','Industry'], axis=1, inplace=True)
学習データを分離し、さらにクレンジングします。 今回は既にクローズされているリードを学習データとします。
train = df[df.Status > -1]
train.drop("Id", axis=1, inplace=True)
col_names = ["AnnualRevenue","NumberOfEmployees"]
features = train[col_names]
scaler = StandardScaler().fit(features.values)
features = scaler.transform(features.values)
train[col_names] = features
X = train.drop("Status", axis=1)
Y = train["Status"]
モデル構築
学習データからモデルを構築します。
model = LogisticRegression()
model.fit(X,Y)
score = model.score(X,Y)
print('Score:'+ str(score))
予測
予測対象のデータはまだクローズしていないリードです。 構築したモデルを使って予測します。
target = df[df.Status == -1]
features = target[col_names]
target[col_names] = scaler.transform(features.values)
ids = target["Id"]
X = target.drop(["Id","Status"], axis=1)
pred = model.predict(X)
pred = pd.concat([pd.Series(pred,name='PredictedStatus'),ids],axis=1)
データ出力
予測結果をSalesforce に格納します。 ここでもSalesforce へのアクセスにCData Python Connectorを使います。
pred['PredictedStatus'] = pred['PredictedStatus'].map({1 : 'Likely converted', 0 : 'Not likely converted'})
conn = mod.connect(CONNECTION_STRING)
sql = "UPDATE Lead SET PredictedStatus__c = ? WHERE Id = ?"
params = pred.values
cur = conn.cursor()
cur.executemany(sql, params)
conn.close()
これで完了です。 全体のソースコードはここから入手できます。
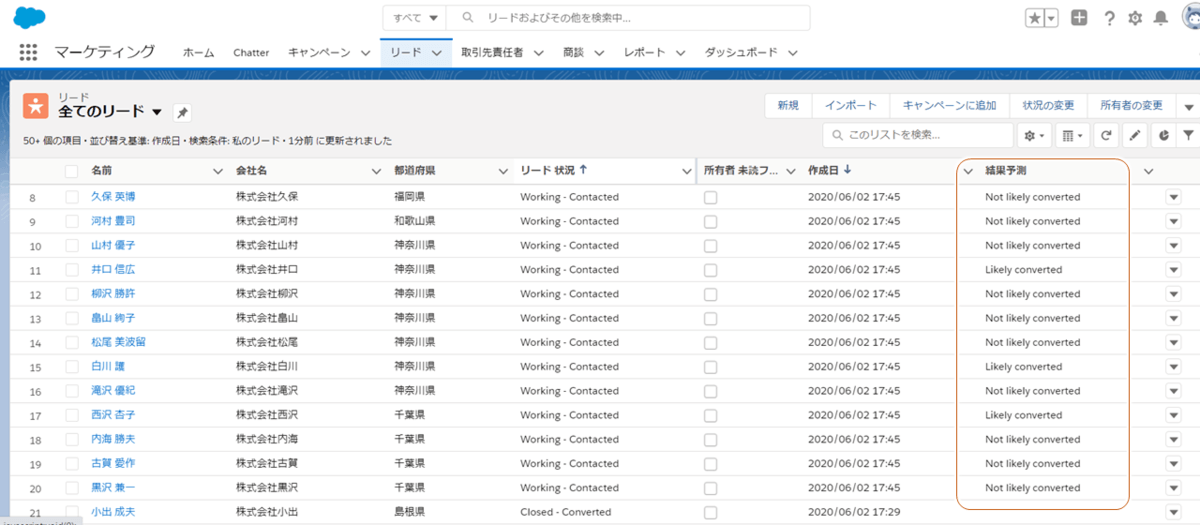
予測の確認
上記コードを実行すると、以下のようにまだクローズしていないリードの「結果予測」フィールドに結果の予測が書き込まれます。
おわりに
本記事ではSalesforce の各リードの特徴からそのリードが取引につながるかどうかを予測し、さらにその結果をSalesforceに書き込む方法を紹介しました。 インターネットにつながるマシンがあれば、Python とその周辺ライブラリをインストールするだけで、予測とシステムへの反映を簡単に行うことができます。
CData Python Connectors
今回Salesforce とのデータ連携にはCData Salesforce Python Connectorを利用しました。 CData Python Connectorsは、Salesforceだけでなく200を超えるクラウドサービスに対するコネクタをラインナップしています。

各コネクタは30日間の評価版が無料で利用できますので、Python とクラウドサービスとのデータ連携を検討している方はぜひお試しください。
関連コンテンツ



