ノーコードでクラウド上のデータとの連携を実現。
詳細はこちら →Apache Spark Data Provider の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!リードエンジニアの杉本です。
Blazor は、.NET を使って対話型のクライアント側Web UI を構築するためのフレームワークです。JavaScript の代わりにC# を使って、UI を作れるところが魅力です。また、既存の.NET ライブラリや.NET エコシステムを使うことができる利点があります。
CData ADO.NET Provider for SparkSQL は、LINQ やEntity Framework などの標準のADO.NET インターフェースを使ってSpark を操作可能にします。Blazor が.NET Core 対応をしているため、Server Side Blazor からADO.NET Provider を使うことができます。この記事では、Server Side Blazor からSpark に接続して直接SQL クエリを実行する方法を説明します。
CData ADO.NET Provider は、通常であればRDB に接続するフレームワークである ADO.NET DataAdapter やLinqToSQL(もしくはDapper などのORM を挟んでもいいです)であり、Spark のデータへもRDB と同感覚でアクセスが可能になります。
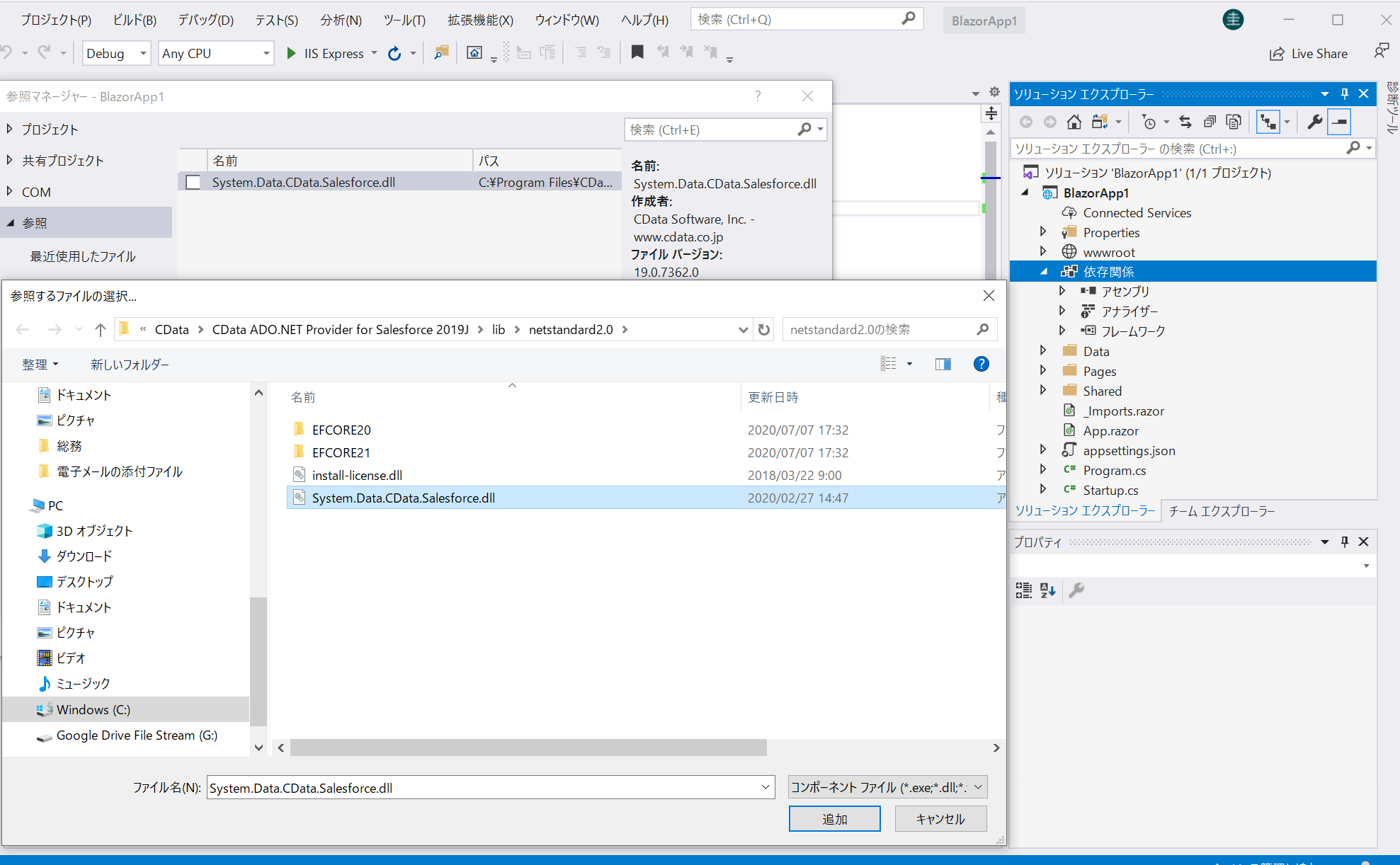
CData のWebsite からProvider をダウンロードして、マシンにインストールします。NuGet からインストールすることも可能です。Spark ADO.NET Data Provider で検索してください。
サンプルプロジェクトの「Page」→「Index.razor」を開きます。
以下のコードを書きます。使っているクエリはおなじみの標準SQL です。Spark 固有のAPI を書かなくてもRDB と同感覚でSQL が書けるところがADO.NET Prover for SparkSQL の強味です。
@page "/"
@using System.Data;
@using System.Data.CData.SparkSQL;
Hello, world!
Welcome to your Data app.
@using (SparkSQLConnection connection = new SparkSQLConnection(
"Server=127.0.0.1;"))
{
var sql = "SELECT City, Balance FROM Customers";
var results = new DataTable();
SparkSQLDataAdapter dataAdapter = new SparkSQLDataAdapter(sql, connection);
dataAdapter.Fill(results);
}
@foreach (DataColumn item in results.Rows[0].Table.Columns)
{
@foreach (DataRow row in results.Rows)
{
@item.ColumnName
}
@foreach (var column in row.ItemArray)
{
}
@column.ToString()
}
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
プロジェクトをリビルドして実行します。このようにSpark からデータを直接取得し、HTML テーブル形式にレンダリングしています。
もちろんSaaS データソースへの接続の場合には、RDB 向けのドライバーと違い最終的にはHTTP リクエストが行われるので、サーバーサイド Blazor としてサーバーサイドから実行されるのか、クライアントサイド Blazor として、実行中のブラウザからHTTPリクエストが行われるのかの違いはあります。そのあたりはネットワークやプロキシの設定として注意が必要でしょう。設定はコード内の接続プロパティで可能です。