Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →




Ready to get started?
Download a free trial of the Apache Spark ODBC Driver to get started:
Download NowLearn more:
The Spark ODBC Driver is a powerful tool that allows you to connect with Apache Spark, directly from any applications that support ODBC connectivity.
The Driver maps SQL to Spark SQL, enabling direct standard SQL-92 access to Apache Spark.
Using the CData ODBC Driver for Spark in PyCharm
Connect to Spark as an ODBC data source in PyCharm using the CData ODBC Driver for Spark.
The CData ODBC Drivers can be used in any environment that supports loading an ODBC Driver. In this tutorial we will explore using the CData ODBC Driver for Spark from within PyCharm. Included are steps for adding the CData ODBC Driver as a data source, as well as basic PyCharm code to query the data source and display results.
To begin, this tutorial will assume that you have already installed the CData ODBC Driver for Spark as well as PyCharm.
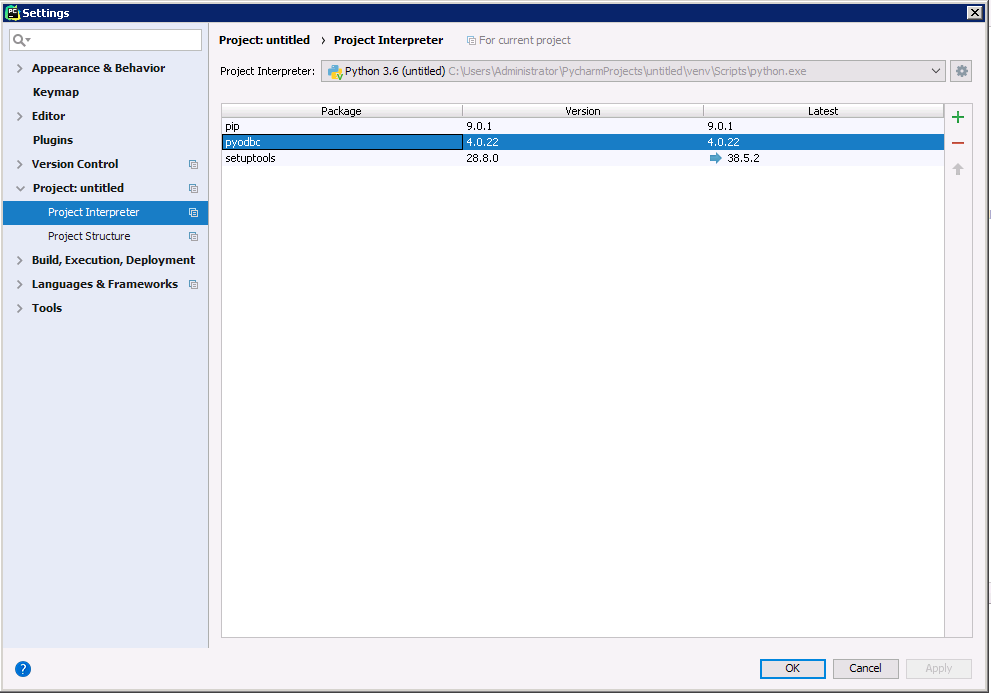
Add Pyodbc to the Project
Follow the steps below to add the pyodbc module to your project.
- Click File -> Settings to open the project settings window.
- Click Project Interpreter from the Project: YourProjectName menu.
- To add pyodbc, click the + button and enter pyodbc.
- Click Install Package to install pyodbc.
Connect to Spark
You can now connect with an ODBC connection string or a DSN. See the Getting Started section in the CData driver documentation for a guide to creating a DSN on your OS.
Set the Server, Database, User, and Password connection properties to connect to SparkSQL.
Below is the syntax for a DSN:
[CData SparkSQL Source]
Driver = CData ODBC Driver for Spark
Description = My Description
Server = 127.0.0.1
Execute SQL to Spark
Instantiate a Cursor and use the execute method of the Cursor class to execute any SQL statement.
import pyodbc
cnxn = pyodbc.connect('DRIVER={CData ODBC Driver for SparkSQL};Server = 127.0.0.1;')
cursor = cnxn.cursor()
cursor.execute("SELECT City, Balance FROM Customers WHERE Country = 'US'")
rows = cursor.fetchall()
for row in rows:
print(row.City, row.Balance)
After connecting to Spark in PyCharm using the CData ODBC Driver, you will be able to build Python apps with access to Spark data as if it were a standard database. If you have any questions, comments, or feedback regarding this tutorial, please contact us at support@cdata.com.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers