各製品の資料を入手。
詳細はこちら →Apache Spark ODBC Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Apache Spark ODBC Driver は、ODBC 接続をサポートするさまざまなアプリケーションからApache Spark データへの接続を実現するパワフルなツールです。
標準SQL とSpark SQL をマッピングして、SQL-92 で直接Apache Spark にアクセス。
CData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
SQL Server のPolyBase は、データベーステーブルをクエリするTransact-SQL 構文を使って、外部データにクエリする仕組みです。 CData ODBC Driver for SparkSQL を組み合わせて使うことで、SQL Server データと同じようにSpark へのアクセスが可能です。 本記事では、外部データソースと外部テーブルの作成から、T-SQL クエリを使ってリアルタイムSpark のデータへ接続を認可するところまで説明します。
CData ODBC ドライバーは、ドライバーに組み込まれた最適化されたデータ処理により、PolyBase でリアルタイムSpark のデータを送受信するための圧倒的なパフォーマンスを提供します。SQL Server からSpark に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をSpark に直接プッシュダウンし、組み込みSQL エンジンを利用して、サポートされていない操作(一般的にはSQL 関数とJOIN 操作) をクライアント側で処理します。また、PolyBase を使用することで、単一のクエリを使用して分散ソースからデータをプルし、SQL Server データをSpark と結合することもできます。
CData ODBC ドライバは、以下のような特徴を持ったリアルタイムデータ連携ソリューションです。
CData ODBC ドライバでは、1.データソースとしてSpark の接続を設定、2.PolyBase 側でODBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
まずは、本記事右側のサイドバーからSparkSQL ODBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
未指定の場合は、初めにODBC DSN(data source name)で接続プロパティを指定します。ドライバーのインストールの最後にアドミニストレーターが開きます。Microsoft ODBC Data Source Administrator を使用して、ODBC DSN を作成および構成できます。PolyBase を使用してSQL Server に外部データソースを作成するには、System DSN を構成します。(CData Spark Sys は自動的に作成されます。)
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
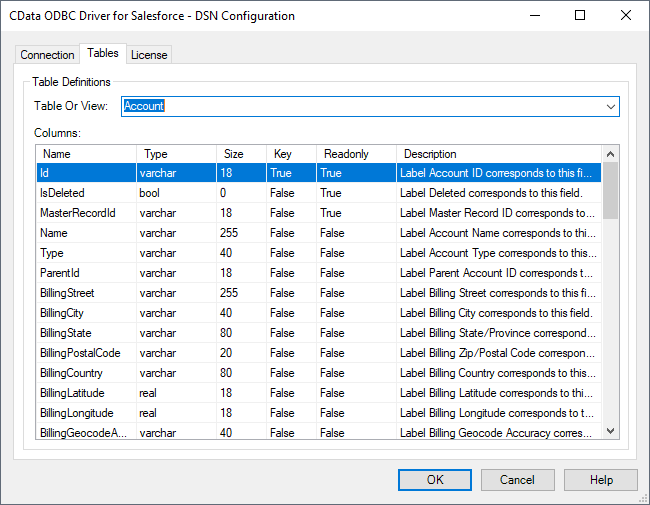
[接続のテスト]をクリックして、DSN がSpark に正しく接続できているかを確認します。[テーブル]タブに移動し、Spark のテーブル定義を確認します。
接続を構成したのち、外部データソースのマスター暗号化キーと資格情報データベースを作成する必要があります。
以下のSQL コマンドを実行して新しいマスターキー[ENCRYPTION]を作成し、外部データソースの資格情報を暗号化します。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
以下のSQL コマンドを実行してSpark に接続されている外部データソースの資格情報を作成します。
Note:Spark は認証にUser やPassword を必要としないため、IDENTITY とSECRET に任意の値を使用できます。
CREATE DATABASE SCOPED CREDENTIAL sparksql_creds WITH IDENTITY = 'username', SECRET = 'password';
以下のSQL コマンドを実行し、以前作成したDSN と資格情報を使用して、PolyBase でSpark の外部データソースを作成します。
PUSHDOWN は、デフォルトでON に設定されているため、ODBC Driver は、サーバー側の処理を利用して複雑なクエリを実行できます。
CREATE EXTERNAL DATA SOURCE cdata_sparksql_source WITH ( LOCATION = 'odbc://SERVERNAME[:PORT]', CONNECTION_OPTIONS = 'DSN=CData Spark Sys', -- PUSHDOWN = ON | OFF, CREDENTIAL = sparksql_creds );
外部データソースを作成したら、CREATE EXTERNAL TABLE ステートメントを使用してSQL Server インスタンスからSpark にリンクします。テーブルカラムの定義は、CData ODBC Driver for SparkSQL によって公開されているものと一致しなければなりません。DSN Configuration Wizard の[テーブル]タブを参照し、テーブルの定義を確認できます。
以下は、Spark Customers に基づいて外部テーブルを作成するステートメントの一例です。
CREATE EXTERNAL TABLE Customers( City [nvarchar](255) NULL, Balance [nvarchar](255) NULL, ... ) WITH ( LOCATION='Customers', DATA_SOURCE=cdata_sparksql_source );
SQL Server インスタンスでSpark の外部テーブルを作成すると、ローカルデータとリモートデータを同時にクエリできるようになります。CData ODBC Driver に組み込まれているクエリ処理により、可能な限り多くのクエリ処理がSpark にプッシュされることで、ローカルのリソースと計算リソースが解放されます。ODBC Driver for SparkSQL の30日間無料トライアルをダウンロードし、SQL Server データでリアルタイムSpark のデータを使い始めましょう。
このようにCData ODBC ドライバと併用することで、270を超えるSaaS、NoSQL データをコーディングなしで扱うことができます。30日の無償評価版が利用できますので、ぜひ自社で使っているクラウドサービスやNoSQL と合わせて活用してみてください。
CData ODBC ドライバは日本のユーザー向けに、UI の日本語化、ドキュメントの日本語化、日本語でのテクニカルサポートを提供しています。