こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
CData Driver for SparkSQL を使って、BI・ビジュアライズツールのTableau からSpark のデータをノーコードで連携して利用できます。この記事では、CData JDBC Driver for SparkSQL を使います。JDBC は、Windows 版のTabelau でもMac 版のTableau でも同じように利用できます。
Tabelau からSpark のデータへの接続を確立
Tableau での操作の前に.jar ファイルを以下のパスに格納します:
- Windows: C:\Program Files\Tableau\Drivers
- MacOS: ~/Library/Tableau/Drivers
.jar ファイルを配置したら、Spark への接続を設定します。
- Tableau を開きます。
- [データ]->[新しいデータソース]を開きます。
- [その他のデータベース(JDBC)]をクリックします。
- URL にJDBC 接続文字列を入力します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
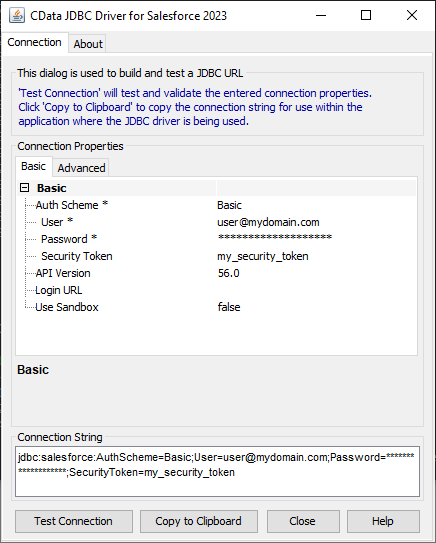
JDBC Driver の接続文字列デザイナーを使う
JDBC 接続文字列を作るには、Spark JDBC Driver のビルトイン接続文字列デザイナーを使う方法があります。ドライバーの.jar ファイルをダブルクリックするか、コマンドラインから.jar ファイルを実行します。
Windows:
java -jar 'C:\Program Files\CData\CData JDBC Driver for SparkSQL 2019\lib\cdata.jdbc.sparksql.jar'
MacOS:
java -jar cdata.jdbc.sparksql.jar
接続プロパティに値を入力して、生成される接続文字列をクリップボードにコピーします。
![接続文字列デザイナーを使って、JDBC URL を生成する (Salesforce is shown.)]()
JDBC URLを設定する際には、Max Rows プロパティを設定することをお勧めします。これにより取得される行数が制限され、パフォーマンスを向上させます。
デザイナーで生成されるJDBC URL のサンプル:
jdbc:sparksql:Server=127.0.0.1;
- 方言:SQL92
- サインインをクリックします。
- 接続エラーの場合には、Java がダウンロードされていない場合、Java が64bit マシン用ではなく32bit 用である、などの場合がありますので確認をお願いします。
スキーマ検出とデータのクエリ
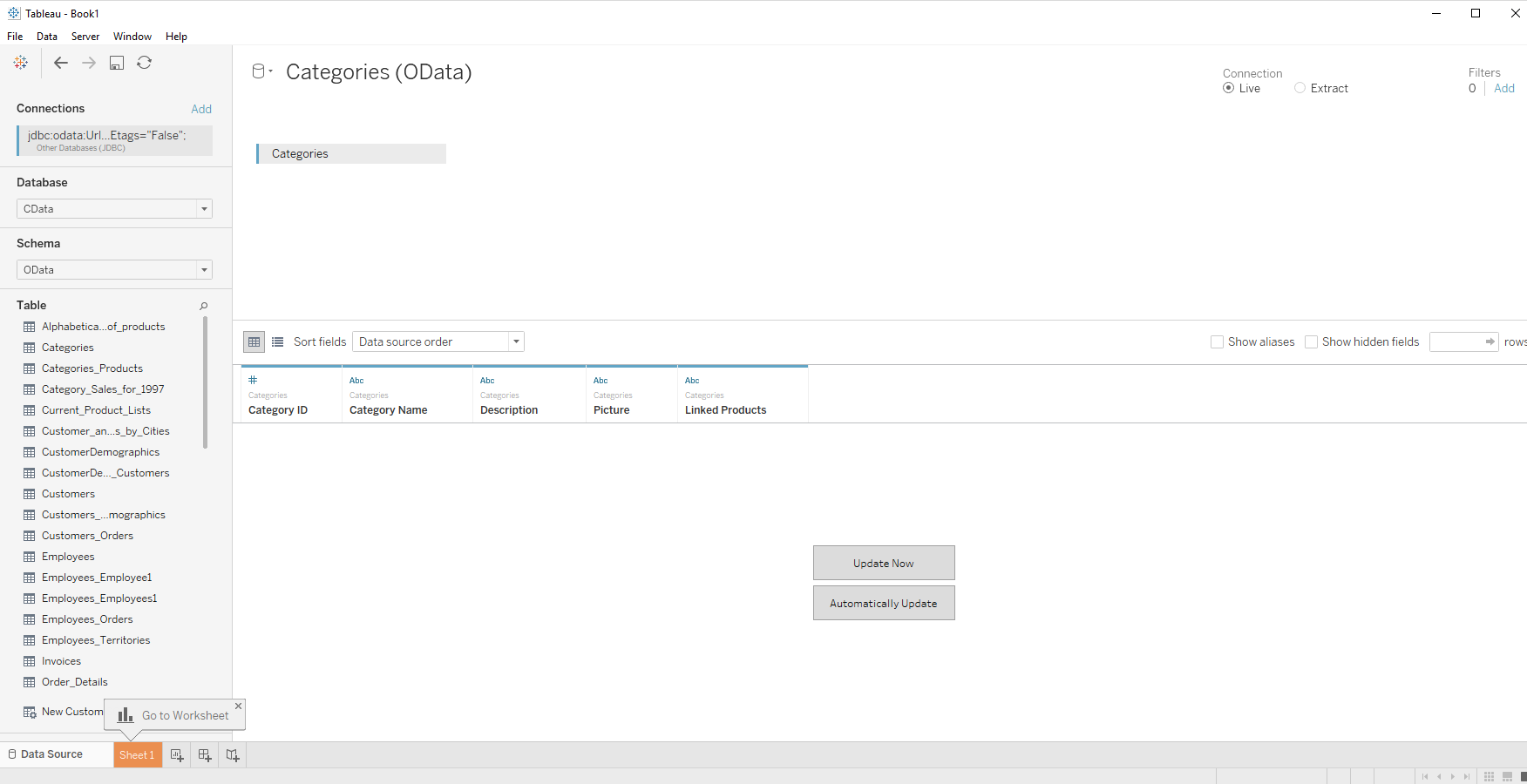
- [データベース]のドロップダウンで、CData を選択します。
- [スキーマ]で、[CData]を選択します。
- テーブルをJOIN エリアにドラッグします。複数のテーブルを選択することも可能です。
![Drag the table onto the join area.]()
- [今すぐ更新]か[自動更新]を選択します。[今すぐ更新]では、はじめの1000行のデータをプレビューで取得します(もしくは表示行を指定するボックスに取得する行数を指定可能
)。[自動更新]では、自動的にデータを取得してプレビューに表示します。
- [接続]メニューでは、[ライブ]もしくは[抽出]を選択します。常にリアルタイムデータを扱いたい場合には、[ライブ]を選択します。
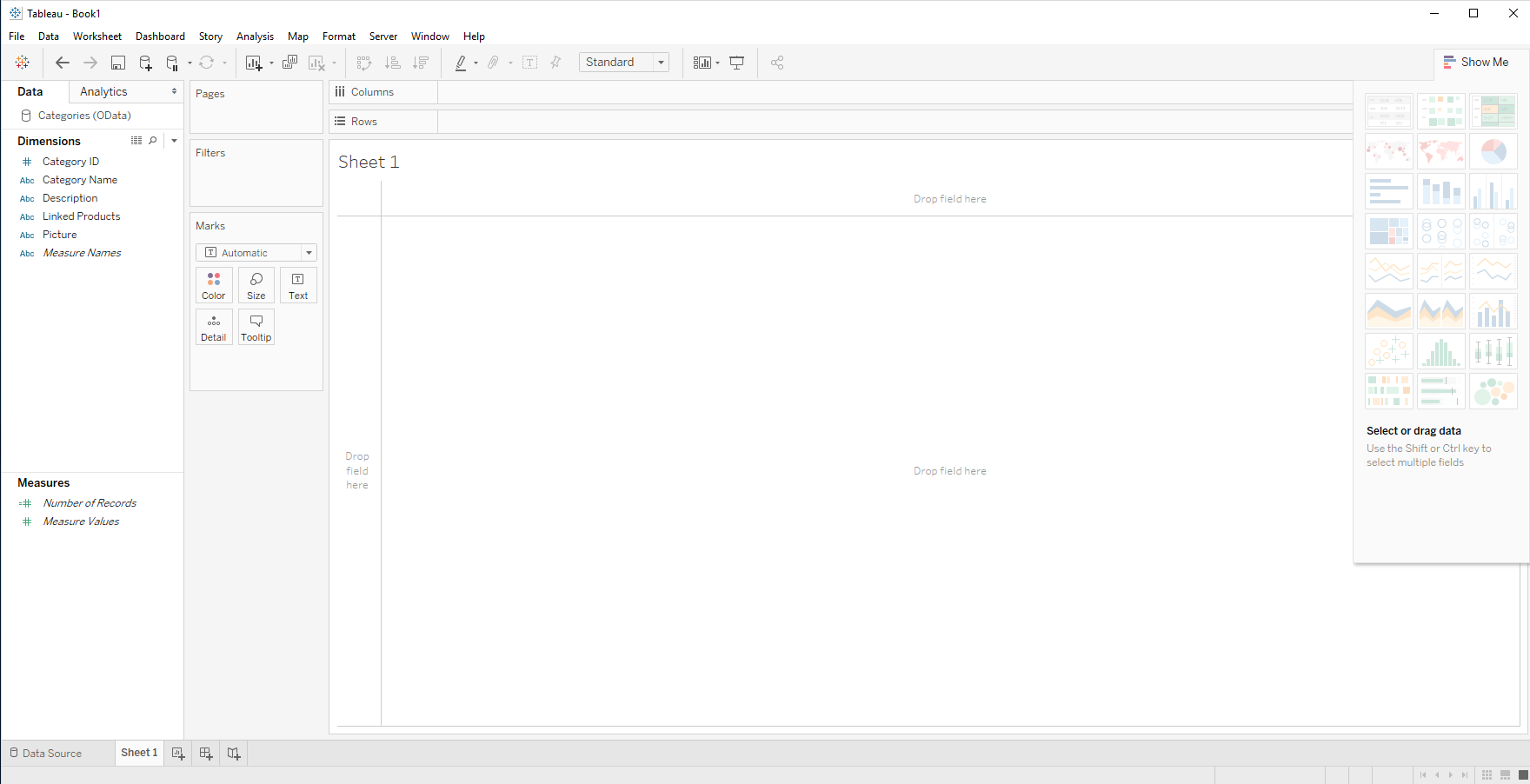
- ワークシートのタブを開きます。CData Driver は、カラム情報やデータ型情報を自動的に検出するので、取得したSpark のデータのカラムはディメンションとメジャーに分けてリスト表示されます。
![Click the tab for your worksheet.]()
- デイメンションやメジャーを列・行のフィールドにドロップして、ビジュアライズを作成します。
CData JDBC Driver for SparkSQL をTabelau で使うことで、ノーコードでSpark のデータをビジュアライズできました。ぜひ、30日の無償評価版 をお試しください。