JReport Designer でSpark のデータを連携
JReport Designer でSpark に連携するチャートとレポートを作成します。
加藤龍彦
デジタルマーケティング
最終更新日:2022-10-10
CData

こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL を使用すると、Spark がリレーショナルデータベースであるかのようにダッシュボードやレポートからリアルタイムデータにアクセスでき、使い慣れたSQL クエリを使用してSpark] をクエリできます。ここでは、JDBC データソースとしてSpark に連携し、JReport Designer でSpark のレポートを作成する方法を説明します。
Spark のデータに接続
- C:\JReport\Designer\bin\setenv.bat を編集し、JAR ファイルの場所をADDCLASSPATH 変数に追加します。
...
set ADDCLASSPATH=%JAVAHOME%\lib\tools.jar;C:\Program Files\CData\CData JDBC Driver for SparkSQL 2016\lib\cdata.jdbc.sparksql.jar;
...
- [File][New][Data Source]と進み、新しいデータソースを作成します。
- 表示されるダイアログで、データソースの名前(CData JDBC Driver for SparkSQL) を作成し、JDBC を選択して[OK]をクリックします。
- [JDBC Connection Information]ダイアログで、JDBC ドライバーへの接続を構成します。
- Driver:[Driver]ボックスにチェックがついていることを確認し、ドライバーのクラスの名前を入力します。
cdata.jdbc.sparksql.SparkSQLDriver
- URL:jdbc:sparksql: から始まり、その後にセミコロンで区切られた接続プロパティのリストが続くJDBC URL を入力します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
ビルトイン接続文字列デザイナー
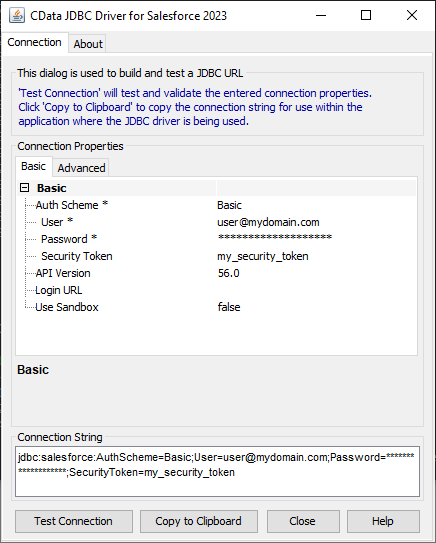
JDBC URL の構成については、Spark JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルのダブルクリック、またはコマンドラインからJAR ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
![Using the built-in connection string designer to generate a JDBC URL (Salesforce is shown.)]()
JDBC URL を構成する際、Max Rows 接続プロパティを設定することもできます。これによって戻される行数を制限するため、可視化・レポートのデザイン設計時のパフォーマンスを向上させるのに役立ちます。
以下は一般的なJDBC URLです。
jdbc:sparksql:Server=127.0.0.1;
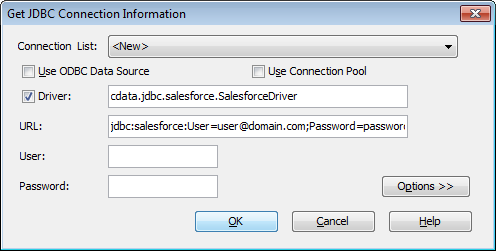
- User:認証に使用するユーザー名は、通常空白のままにします。
- Password:User と同様に認証に使用するパスワードも、通常は空白のままにします。
![Configuring the connection to the JDBC Driver (Salesforce is shown.)]()
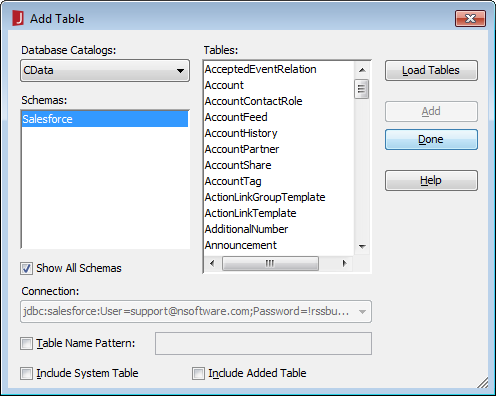
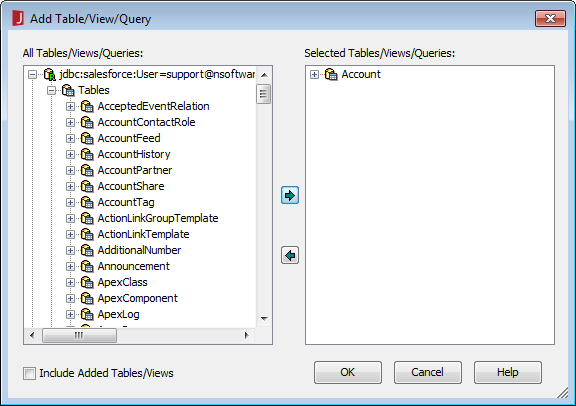
[Add Table]ダイアログで、レポート(またはこのデータソースを使用する予定のレポート)に含めるテーブルを選択し、[Add]をクリックします。
![Adding Tables.(Salesforce is shown.)]()
ダイアログがテーブルのロードを完了したら、[Done]をクリックします。
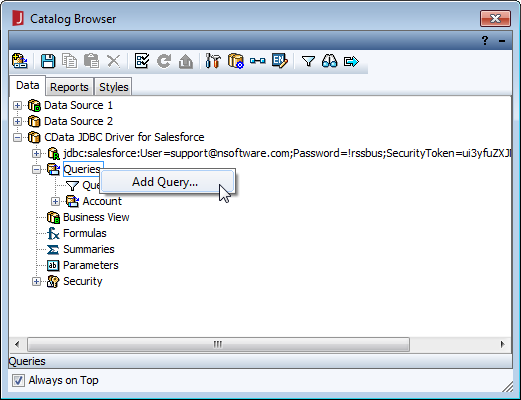
- [Catalog Browser]では、レポートの作成に使用するクエリを作成できます。今すぐ、またはレポートの作成後に作成できますが、どちらにしても、 データソース(CData JDBC Driver for Spark) を展開()し、[Queries]を右クリックして[Add Query]を選択します。
![Adding a query for data to be used in the report.(Salesforce is shown.)]()
- [Add Table/View/Query]ダイアログで、JDBC URL とTables を展開() し、クエリで使用するテーブルを選択して[OK]をクリックします。
![Selecting a table for the query.(Salesforce is shown.)]()
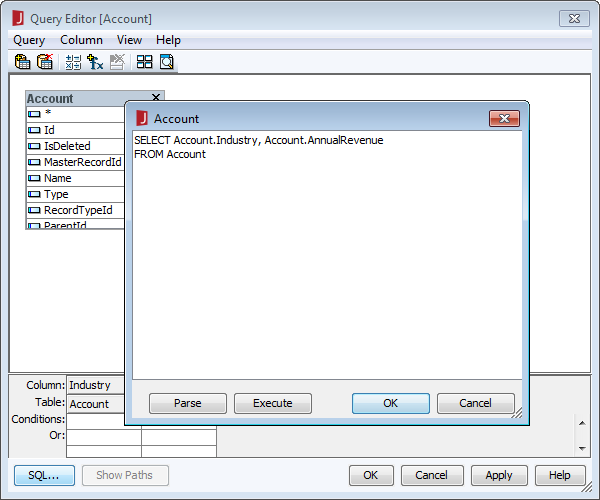
- [Query Editor]ダイアログで、含めるカラムを選択するか、[SQL]ボタンをクリックして以下のようにカスタムクエリを手動で入力できます。
SELECT City, Balance FROM Customers
![Editing the query.(Salesforce is shown.)]()
クエリが作成されたら、[OK]をクリックして[Query Editor]ダイアログを閉じます。この時点で、Spark を新規または既存のレポートに追加する準備が整いました。
NOTE: クエリが作成されると、クエリに基づいて[Business View]を作成できます。[Business View]を使用すると、クエリに基づいてWeb レポートまたはライブラリコンポーネントを作成できます。これについてのより詳しい情報は、JReport のチュートリアルを参照してください。
レポートにSpark のデータを追加
Spark を使用してレポートを作成することができるようになりました。
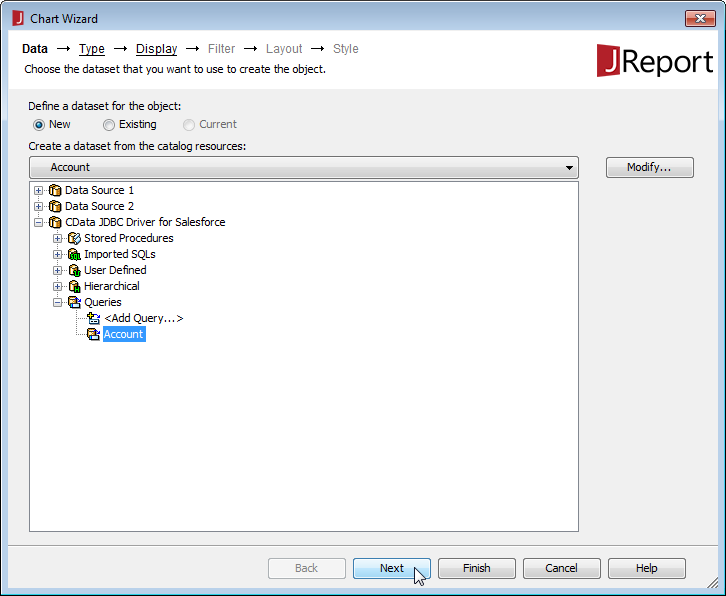
- 新しいレポートを作成([File][New][Page Report]) するか、既存のレポートの[Chart Wizard]を開きます。
- クエリを選択(または上記を参照して新しいクエリを作成) します。
![Selecting the query to use.(Salesforce is shown.)]()
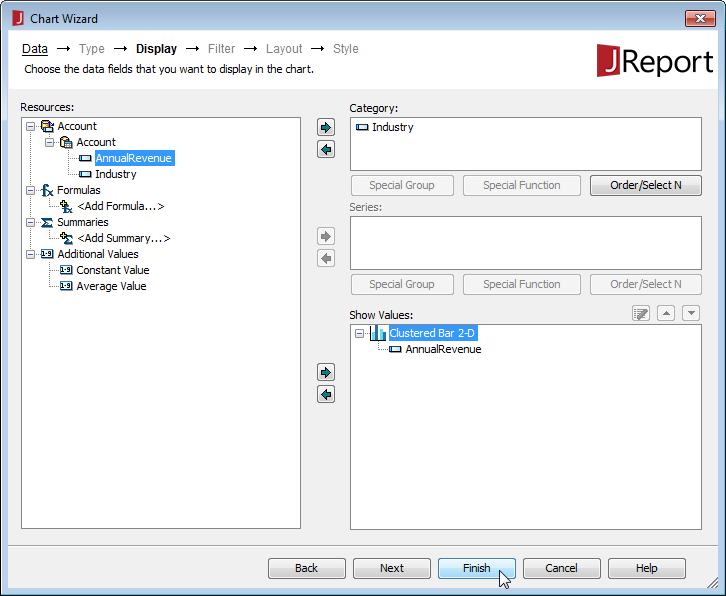
- クエリのカラムからグラフの[Category]と[Value]を割り当て、[Finish]をクリックします。
![Assigning columns to define the chart.(Salesforce is shown.)]()
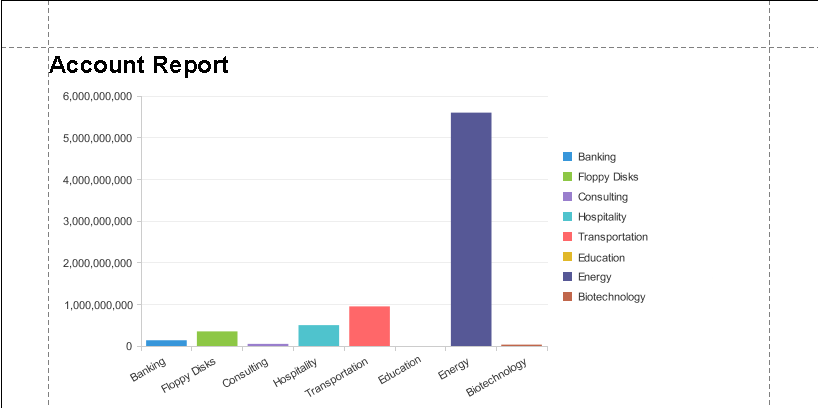
- レポートの[View]タブをクリックし、チャートを表示します。
![Sample chart based on live data.(Salesforce is shown.)]()
関連コンテンツ