Denodo Platform でSpark のデータソースを作成
CData JDBC ドライバを使ってDenodo Virtual DataPort Administrator でSpark のデータ の仮想データソースを作成します。
桑島義行
テクニカルディレクター
最終更新日:2022-02-28
CData

こんにちは!テクニカルディレクターの桑島です。
Denodo Platform は、エンタープライズデータベースのデータを一元管理するデータ仮想化製品です。CData JDBC Driver for SparkSQL と組み合わせると、Denodo ユーザーはリアルタイムSpark のデータと他のエンタープライズデータソースを連携できるようになります。この記事では、Denodo Virtual DataPort Administrator でSpark の仮想データソースを作成する手順を紹介します。
最適化されたデータ処理が組み込まれたCData JDBC Driver は、リアルタイムSpark のデータを扱う上で比類のないパフォーマンスを提供します。Spark にSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をSpark に直接渡し、サポートされていない操作(主にSQL 関数とJOIN 操作)は組み込みSQL エンジンを利用してクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブデータ型を使ってSpark のデータを操作および分析できます。
Spark Virtual Port を作成
Denodo からリアルタイムSpark のデータに接続するには、JDBC Driver のJAR ファイルをDenodo の外部ライブラリディレクトリにコピーし、Virtual DataPort Administration Tool から新しいJDBC データソースを作成する必要があります。
- CData JDBC Driver for SparkSQL インストーラーをダウンロードしてパッケージを展開し、JAR ファイルを実行してドライバーをインストールします。
- JAR ファイル(およびライセンスファイルがある場合はそれも)をインストール先(通常はC:\Program Files\CData\CData JDBC Driver for SparkSQL\lib\)からDenodo 外部ライブラリディレクトリ(C:\Denodo\Denodo Platform\lib-external\jdbc-drivers\cdata-sparksql-19)にコピーします。
- Denodo Virtual DataPort Administration Tool を開き、Server Explorer タブに移動します。
- 「admin」を右クリックし、「New」->「Data source」->「JDBC」を選択します。
![新しいJDBC データソースを作成]()
- JCBC Connection を設定します。
- Name:任意の名前(例:sparksql)
- Database adapter:Generic
- Driver class path:C:\Denodo\Denodo Platform\lib-external\jdbc-drivers\cdata-sparksql-19
- Driver class:cdata.jdbc.sparksql.SparkSQLDriver
Database URI:必要な接続プロパティを使用してJDBC のURL に設定。例えば次のようになります。
jdbc:sparksql:Server=127.0.0.1;
![JDBC コネクションを設定(NetSuite の場合)]()
Database URI の作成については以下を参照してください。
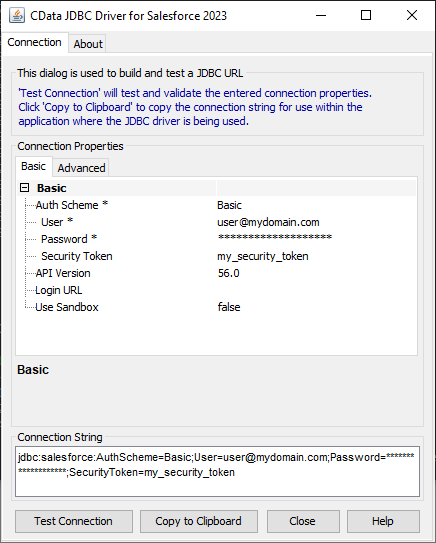
組み込みの接続文字列デザイナー
JDBC URL の作成の補助として、Spark JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
![組み込みの接続文字列デザイナーを使ってJDBC URL を生成(Salesforce の場合)]()
- 「接続テスト」をクリックして設定を確認し、「保存」をクリックします。
Virtual DataPort Administration Tool でSpark のデータを表示
データソースを作成したら、Denodo Platform で使用するSpark のデータの基本ビューを作成できます。
- 新しく作成したVirtualPort(admin.SparkSQL)で「Create base view」をクリックします。
- オブジェクトツリーを展開し、インポートしたいオブジェクト(テーブル)を選択します。
![インポートするオブジェクトの選択(NetSuite の場合)]()
- 「Create selected」をクリックしてSpark のデータのビューを作成します。
オプション:「Create associations from foreign keys」をクリックして、オブジェクト間の関係を定義します。
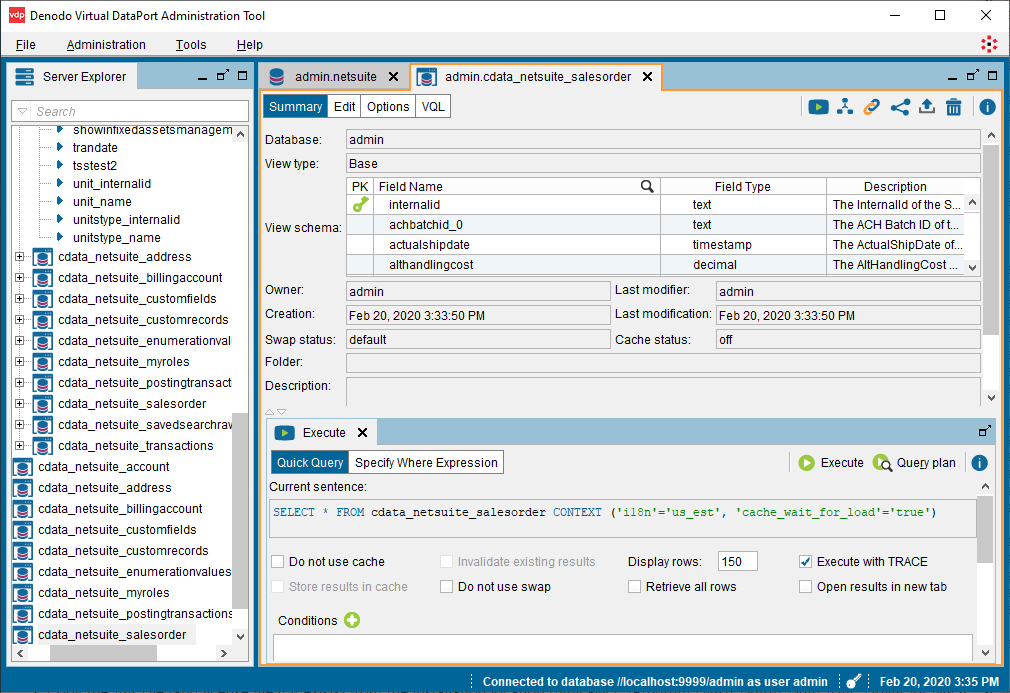
- ビューを作成した状態で、Server Explorer のテーブル(cdata_sparksql_customers)に移動し、選択したテーブルをダブルクリックします。
- 新しいタブで「Execution panel」をクリックしてクエリパネルを開きます。
- 「Execute」タブでクエリをカスタマイズするか、デフォルトを使用します。
SELECT * FROM cdata_sparksql_customers CONTEXT ('i18n'='us_est', 'cache_wait_for_load'='true')
![データを表示するクエリを設定]()
- 「Execute」をクリックすると、データが表示されます。
![データを表示]()
基本ビューを作成すると、Denodo Platform の他のデータソースと同様にリアルタイムSpark のデータを操作できるようになります。例えば、Denodo Data Catalog でSpark にクエリを実行できます。
CData JDBC Driver for SparkSQL の30日の無償評価版をダウンロードして、Denodo Platform でリアルタイムSpark のデータの操作をはじめましょう!ご不明な点があれば、サポートチームにお問い合わせください。
関連コンテンツ