こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL は、IDE からBI ツールまで、サードパーティーツールからSpark のデータの読み書きを可能にするJDBC 標準を提供します。本記事では、DBeaver のウィザードを使ってSpark のデータに接続し、GUI 上でデータを参照する方法を紹介します。
CData JDBC ドライバとは?
CData JDBC ドライバは、以下の特徴を持ったリアルタイムデータ接続ツールです。
- Spark をはじめとする、CRM、MA、グループウェア、広告、会計ツールなど多様な270種類以上のSaaS / DB に対応
- DBeaver を含む多様なアプリケーション、ツールにSpark のデータを連携
- ノーコードでの手軽な接続設定
- 標準 SQL での柔軟なデータ読み込み・書き込み
CData JDBC ドライバでは、1.データソースとしてSpark の接続を設定、2.DBeaver 側でJDBC Driver との接続を設定、という2つのステップだけでデータソースに接続できます。以下に具体的な設定手順を説明します。
CData JDBC ドライバのインストールとSpark への接続設定
まずは、本記事右側のサイドバーからSparkSQL JDBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
次に、以下の手順でDBeaver にドライバーのJAR ファイルをロードします。
- DBeaver アプリケーションを開き、「データベース」メニューの「ドライバーマネジャー」オプションを選択します。「新規」をクリックして「新しいドライバを作成する」フォームを開きます。
- 設定タブで:
- ドライバ名をわかりやすい名前に設定します(例:CData JDBC Driver for Spark)。
- クラス名をJDBC ドライバーのクラス名「cdata.jdbc.sparksql.SparkSQLDriver」に設定します。
- URL テンプレートをjdbc:sparksql: に設定します。
![新しいドライバーの設定(Salesforce の場合)。]()
- ライブラリタブで「ファイルを追加」をクリックし、インストールディレクトリ(C:\Program Files\CData\CData JDBC Driver for Spark XXXX\)の「lib」フォルダに移動してJAR ファイル(cdata.jdbc.SparkSQL.jar)を選択します。
![JDBC JAR ファイルをロード(Salesforce の場合)。]()
Spark のデータの接続を作成
以下の手順で、認証情報およびその他の必要な接続プロパティを追加します。
- 「データベース」メニューで、「新しい接続」をクリックします。
- 表示される「新しい接続を作成する」 ウィザードで、先ほど作成したドライバー(例:CData JDBC Driver for Spark)を選択し、「次へ >」をクリックします。
![ドライバーを選択(Salesforce の場合)。]()
- 設定ウィザードの一般タブで、以下を参考に必要な接続プロパティを使用してJDBC URL を設定します。
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
組み込みの接続文字列デザイナー
JDBC URL の作成の補助として、Spark JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
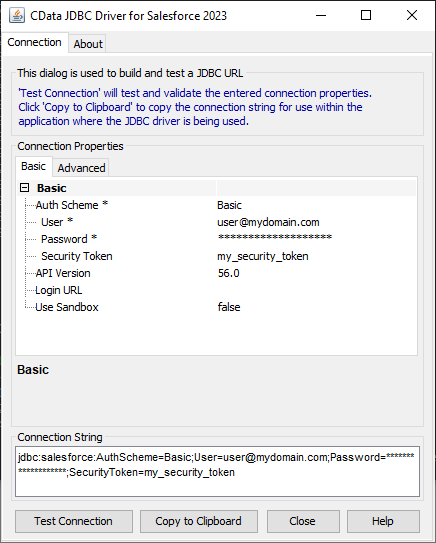
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
![組み込みの接続文字列デザイナーを使ってJDBC URL を生成(Salesforce の場合)]()
一般的な接続文字列:
jdbc:sparksql:Server=127.0.0.1;
![JDBC URL を設定(Salesforce の場合)。]()
- 「テスト接続」をクリックして、接続が正しく設定されていることを確認します。
![正しく設定された接続(Salesforce の場合)。]()
- 「終了」をクリックします。
Spark のデータにクエリを実行
これで、接続できたことで公開されたテーブルのデータにクエリを実行できるようになりました。テーブルを右クリックし、「ビュー表」をクリックします。「データ」タブでデータを確認できます。
![DBeaver でのクエリの結果(Salesforce の場合)。]()
おわりに
CData JDBC Driver for SparkSQL の
30日間無償トライアル
をダウンロードして、DBeaver でリアルタイムSpark のデータの操作をはじめましょう!ご不明な点があれば、
サポートチームにお問い合わせください。