各製品の資料を入手。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへCData


こんにちは!ドライバー周りのヘルプドキュメントを担当している古川です。
Adobe ColdFusion は、Web アプリケーションおよびモバイルアプリケーション開発プラットフォームです。独自のスクリプト言語であるColdFusion Markup Language(CFML)を使用し、データドリブンなWeb サイトを作成したり、REST などのリモートサービスを生成したりすることができます。
ColdFusion とCData JDBC Driver for SparkSQL を組み合わせると、ColdFusion のWeb アプリケーションやモバイルアプリケーションを、運用中のSpark のデータにリンクできます。 これにより、アプリケーションの堅牢性と完成度を高めることができます。この記事では、JDBC ドライバーを使ってColdFusion マークアップファイルからSpark のデータを入力したテーブルを作成する方法について詳しく説明します。
最適化されたデータ処理が組み込まれたCData JDBC ドライバは、リアルタイムSpark のデータを扱う上で高いパフォーマンスを提供します。 Spark にSQL クエリを発行すると、CData ドライバーはフィルタや集計などのSpark 側でサポートしているSQL 操作をSpark に直接渡し、サポートされていない操作(主にSQL 関数とJOIN 操作)は組み込みSQL エンジンを利用してクライアント側で処理します。 組み込みの動的メタデータクエリを使用すると、ネイティブのデータ型を使ってSpark のデータを操作および分析できます。
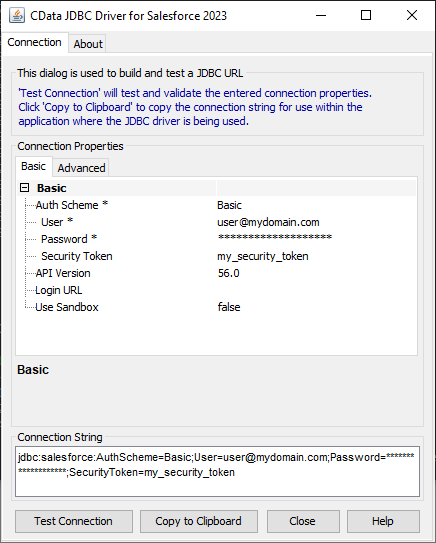
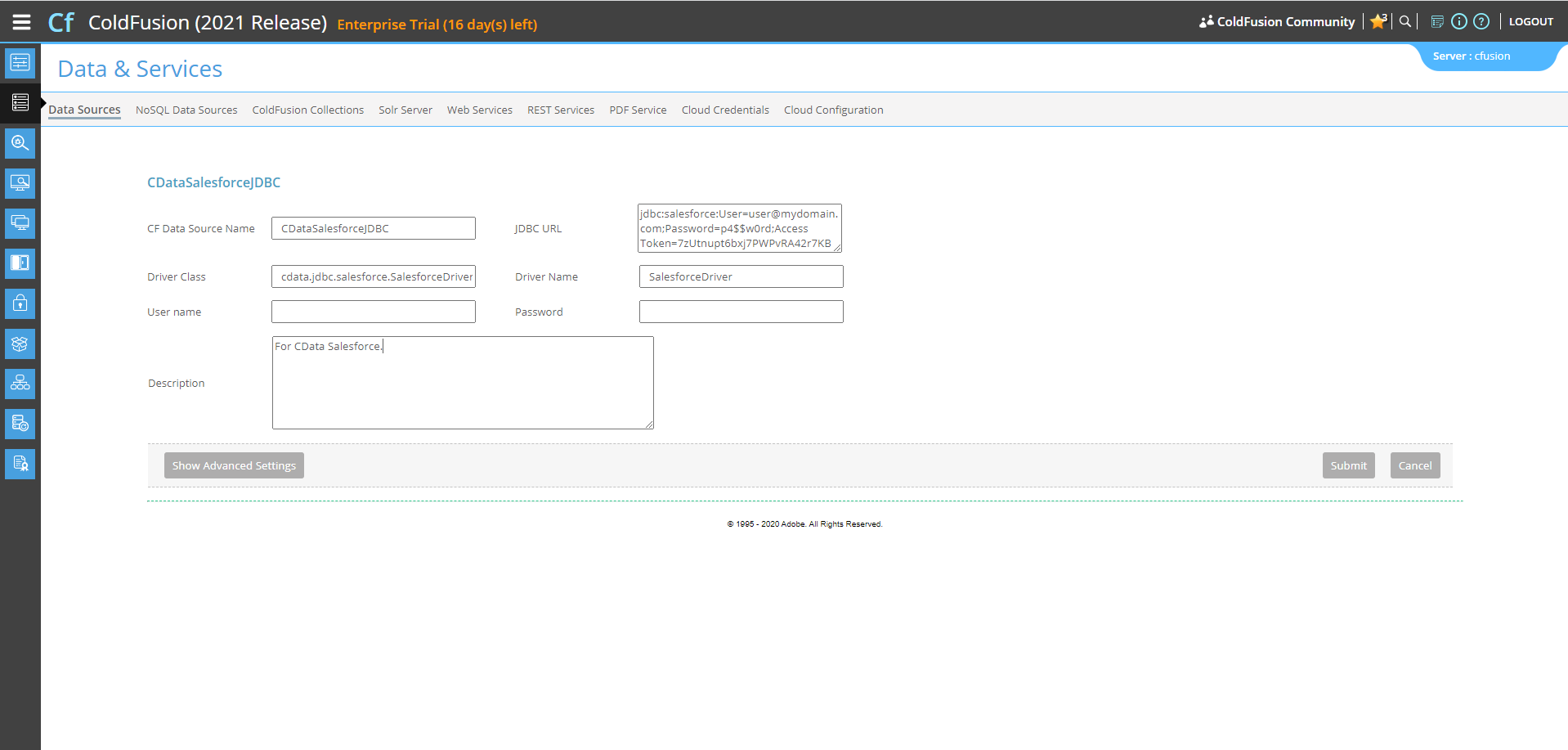
Coldfusion とSpark の接続を確立するには、JDBC 接続文字列が必要です。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
JDBC URL の作成の補助として、Spark JDBC Driver に組み込まれている接続文字列デザイナーが使用できます。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
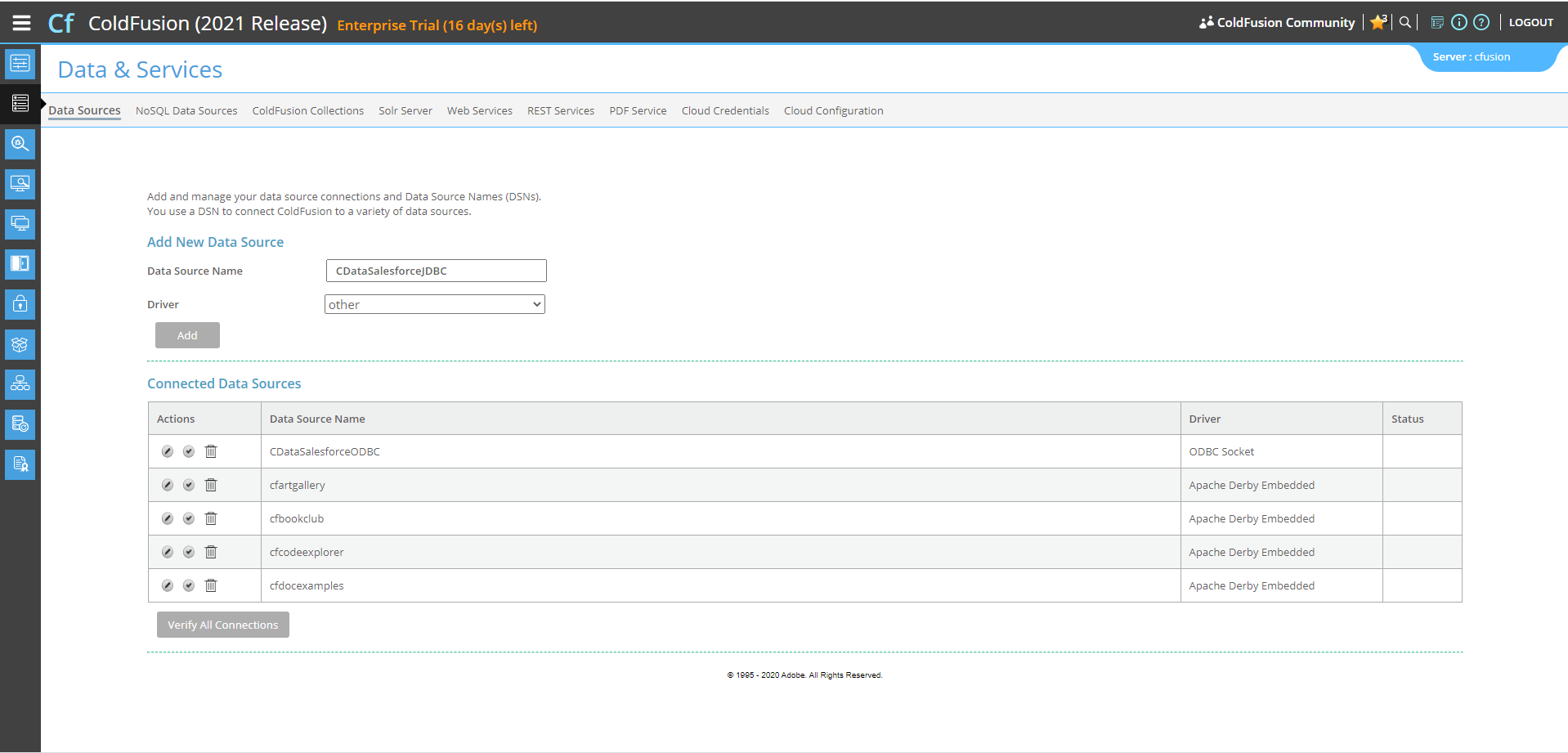
接続を設定したのち、次の手順に従ってはじめにCData JDBC ドライバをColdFusion のlib ディレクトリに追加し、続けて新しいデータソースを追加、接続をテスト、ColdFusion マークアップファイルを作成し、最後にSpark のデータとリアルタイム接続してColdFusion Markup Language(CFML)で記述されるテーブルに表示します。
cdata.jdbc.sparksql.jar
cdata.jdbc.sparksql.lic
Note:.lic ファイルをjar ファイルとともにコピーしないと、有効なライセンスがインストールされていないことを示すライセンスエラーが表示されます。 これは評価版、製品版ともに同様です。
jdbc:sparksql:Server=127.0.0.1;
次のコードは、データソースにクエリを実行します。
<cfquery name="SparkQuery" dataSource="CDataSparkJDBC">
SELECT * FROM Customers
</cfquery>
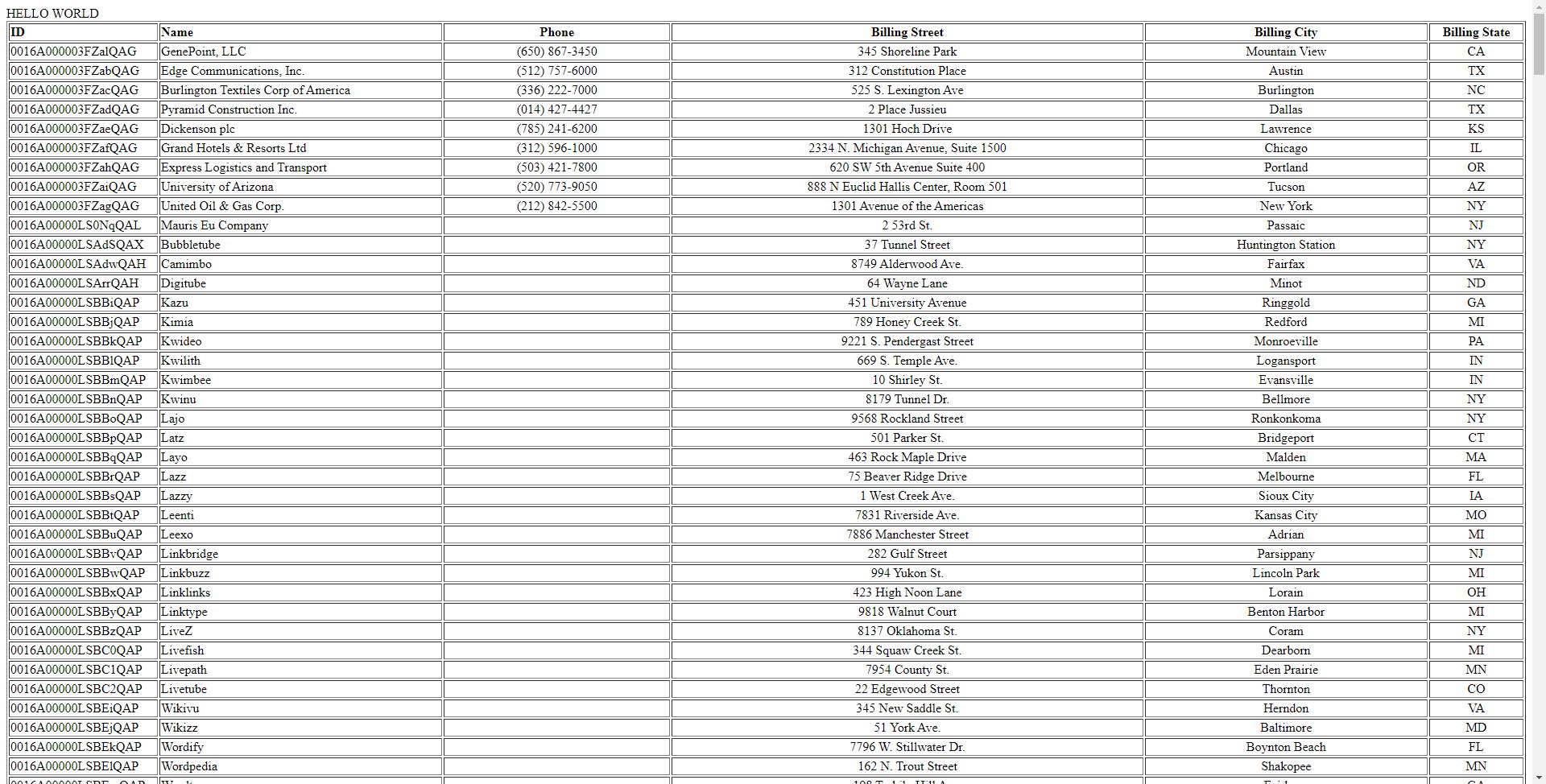
CFTable を使用すると、HTML で素早くテーブルを出力できます。
<cftable
query = "SparkQuery"
border = "1"
colHeaders
colSpacing = "2"
headerLines = "2"
HTMLTable
maxRows = "500"
startRow = "1">
<cfcol header="<b>City</b>" align="Left" width=2 text="City"/>
<cfcol header="<b>Balance</b>" align="Left" width=15 text="Balance"/>
...
</cftable>
HTML 部分を含むコード全体を以下に掲載します。
<html>
<head><title>CData Software | Spark Customers Table Demo </title></head>
<body>
<cfoutput>#ucase("Spark Customers Table Demo")#</cfoutput>
<cfquery name="SparkQuery" dataSource="CDataSparkJDBC">
SELECT * FROM Customers
</cfquery>
<cftable
query = "SparkQuery"
border = "1"
colHeaders
colSpacing = "2"
headerLines = "2"
HTMLTable
maxRows = "500"
startRow = "1">
<cfcol header="<b>City</b>" align="Left" width=2 text="City"/>
<cfcol header="<b>Balance</b>" align="Left" width=15 text="Balance"/>
...
</cftable>
</body>
</html>
なお、CData JDBC ドライバはcfqueryparam 要素を使用したパラメータ化クエリもサポートしています。
次に例を示します。
SELECT * FROM Account WHERE name =
CData JDBC Driver for SparkSQL の 30日間無償トライアル をダウンロードして、Adobe ColdFusion でSpark と連携したアプリケーションの作成をはじめましょう!ご不明な点があれば、サポートチームにお問い合わせください。