各製品の資料を入手。
詳細はこちら →Apache Spark Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへこんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
Apache Camel は、データを消費または生成するさまざまなシステムを統合できる、オープンソースの統合フレームワークです。CData JDBC Driver for SparkSQL と組み合わせることで、リアルタイムSpark のデータと連携するCamel ルートを使用するJava アプリを作成できます。この記事では、Spark のデータをJSON ファイルに接続、クエリ、及びルーティングするアプリをNetBeans で作成する方法について説明します。
ビルトインの最適化されたデータ処理により、CData JDBC Driver は、リアルタイムSpark のデータとやり取りする際に比類のないパフォーマンスを提供します。Spark に複雑なSQL クエリを発行すると、ドライバーはフィルタや集計などのサポートされているSQL 操作をSpark に直接プッシュし、組み込まれたSQL エンジンを利用してサポートされていない操作(主にSQL 関数とJOIN 操作)をクライアント側で処理します。組み込みの動的メタデータクエリを使用すると、ネイティブデータソース型を使用してSpark のデータを操作および分析することができます。
以下の手順に従って、新しいJava プロジェクトを作成し、適切な依存関係を追加します。
プロジェクトが作成されたら、アプリからリアルタイムSpark のデータを操作するために必要な依存関係を追加できるようになります。まだMaven を環境にインストールしていない場合、CData JDBC ドライバのJAR ファイルをプロジェクトに追加するのに必要なため、インストールしてください。
mvn install:install-file -Dfile="C:\Program Files\CData\CData JDBC Driver for SparkSQL 2019\lib\cdata.jdbc.sparksql.jar" -DgroupId="org.cdata.connectors" -DartifactId="cdata-sparksql-connector" -Dversion="19" -Dpackaging=jar
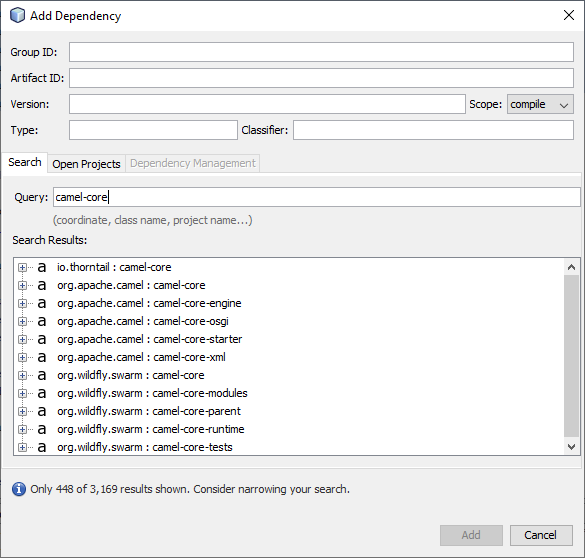
JDBC Driver をインストールしたら、プロジェクトに依存関係を追加できます。依存関係を追加するには、pom.xml を編集するか、依存関係にあるフォルダを右クリックして「Add Dependency」をクリックします。各依存関係のプロパティは以下の通りですが、「Add Dependency」ウィザードの「Query」ボックスに依存関係の名前を入力することで使用可能なライブラリを検索できます。
| Dependency | Group ID | Artifact ID | Version |
|---|---|---|---|
| camel-core | org.apache.camel | camel-core | 3.0.0 |
| camel-jackson | org.apache.camel | camel-jackson | 3.0.0 |
| camel-jdbc | org.apache.camel | camel-jdbc | 3.0.0 |
| camel-jsonpath | org.apache.camel | camel-jsonpath | 3.0.0 |
| cdata-sparksql-connector | org.cdata.connectors | cdata-salesforce-connector | 19 |
| commons-dbcp2 | org.apache.commons | commons-dbcp2 | 2.7.0 |
| slf4j-log4j12 | org.slf4j | slf4j-log4j12 | 1.7.30 |
| log4j | org.apache.logging.log4j | log4j | 2.12.1 |
必要な依存関係を追加したら、Java DSL(Domain Specific Language)を使用してリアルタイムSpark のデータにアクセスできるルートを作成できます。以下はコードの一部です。サンプルプロジェクト(zip ファイル)をダウンロードして以下を実行してください。(TODO コメントに注意してください。)
必要なクラスをメインクラスにインポートすることから始めます。
import org.apache.camel.CamelContext; import org.apache.camel.builder.RouteBuilder; import org.apache.camel.impl.DefaultCamelContext; import org.apache.camel.support.SimpleRegistry; import org.apache.commons.dbcp2.BasicDataSource; import org.apache.log4j.BasicConfigurator;
次に、main メソッドでロギングを構成し、新しいBasicDataSource を作成してレジストリに追加し、新しいCamelContext を作成して、最後にコンテクストへのルートに追加します。この例では、Spark のデータをJSON ファイルにルーティングします。
BasicConfigurator.configure();
BasicDataSource を作成し、ドライバークラス名(cdata.jdbc.salesforce.SalesforceDriver)とURL(必要な接続プロパティを使用)を設定します。
SparkSQL への接続を確立するには以下を指定します。
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、 「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
BasicDataSource basic = new BasicDataSource();
basic.setDriverClassName("cdata.jdbc.sparksql.SparkSQLDriver");
basic.setUrl("jdbc:sparksql:Server=127.0.0.1;");
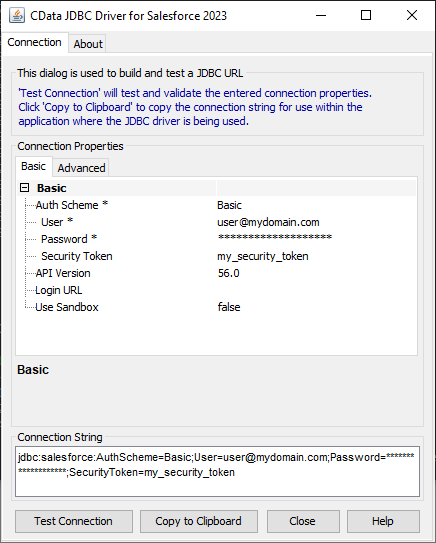
CData JDBC ドライバには、接続URL の構成に役立つ組み込みの接続文字列デザイナーが含まれています。
JDBC URL の構築については、Spark JDBC Driver に組み込まれている接続文字列デザイナーを使用してください。JAR ファイルをダブルクリックするか、コマンドラインからjar ファイルを実行します。
java -jar cdata.jdbc.sparksql.jar
接続プロパティを入力し、接続文字列をクリップボードにコピーします。
SimpleRegistry reg = new SimpleRegistry();
reg.bind("myDataSource", basic);
CamelContext context = new DefaultCamelContext(reg);
以下のルーティングでは、timer コンポーネントを使用して一度実行し、SQL クエリをJDBC Driver に渡します。結果はJSON として整理され、(きれいに印刷できるようにフォーマットされて)file コンポーネントに渡され、JSON ファイルとしてディスクに書き込まれます。
context.addRoutes(new RouteBuilder() {
@Override
public void configure() {
from("timer://foo?repeatCount=1")
.setBody(constant("SELECT * FROM Account LIMIT 10"))
.to("jdbc:myDataSource")
.marshal().json(true)
.to("file:C:\\Users\\USER\\Documents?fileName=account.json");
}
});
ルートを定義したら、CamelContext を開始してライフサイクルを始めます。この例では、10 秒待機してからコンテクストをシャットダウンします。
context.start(); Thread.sleep(10000); context.stop();
これで、Camel を使用してSpark からJSON ファイルにデータをルーティングするJava アプリケーションを使用できるようになりました。CData JDBC Driver for SparkSQL の30日の無償評価版と、サンプルプロジェクトをダウンロードして(TODO コメントに注意して)、Apache Camel でリアルタイムSpark のデータの操作を開始します。ご不明な点があれば、サポートチームにお問い合わせください。