Aqua Data Studio からSpark のデータに連携
Spark のデータにAqua Data Studio のVisual Query Builder やTable Data Editor からデータ連携。
加藤龍彦
デジタルマーケティング
最終更新日:2022-08-10
CData

こんにちは!ウェブ担当の加藤です。マーケ関連のデータ分析や整備もやっています。
CData JDBC Driver for SparkSQL は、Aqua Data Studio のようなIDE のウィザード・アナリティクスにSpark のデータを統合します。本記事では、Spark のデータをコネクションマネージャーに接続してクエリを実行する手順を説明します。
JDBC Data Source の設定
コネクションマネージャーで、新しいJDBC データソースとして、接続プロパティ設定を行い、保存します。Spark のデータがAqua Data Studio ツールから使えるようになります。
- Aqua Data Studio で、Server メニューから Register Server を選択します。
- Register Server フォームで、 'Generic - JDBC' コネクションを選びます。
- 次のJDBC 接続プロパティを設定します:
- Name:任意の名前、データソースの名前など。
- Driver Location:Browse ボタンをクリックして、インストールディレクトリのlib フォルダの cdata.jdbc.sparksql.jar ファイルを選択します。
- Driver:クラス名に cdata.jdbc.sparksql.SparkSQLDriver を入力。
- URL:jdbc:sparksql: から始まるJDBC URL を入力します。接続プロパティをカンマ区切りで書きます。接続プロパティの詳細は、ヘルプドキュメントを参照してください。一般的な接続文字列は:
jdbc:sparksql:Server=127.0.0.1;
![The JDBC data source, defined by the JAR path, driver class, and JDBC URL.(QuickBooks is shown.)]()
SparkSQL への接続
SparkSQL への接続を確立するには以下を指定します。
- Server:SparkSQL をホストするサーバーのホスト名またはIP アドレスに設定。
- Port:SparkSQL インスタンスへの接続用のポートに設定。
- TransportMode:SparkSQL サーバーとの通信に使用するトランスポートモード。有効な入力値は、BINARY およびHTTP です。デフォルトではBINARY が選択されます。
- AuthScheme:使用される認証スキーム。有効な入力値はPLAIN、LDAP、NOSASL、およびKERBEROS です。デフォルトではPLAIN が選択されます。
Databricks への接続
Databricks クラスターに接続するには、以下の説明に従ってプロパティを設定します。Note:必要な値は、「クラスター」に移動して目的のクラスターを選択し、
「Advanced Options」の下にある「JDBC/ODBC」タブを選択することで、Databricks インスタンスで見つけることができます。
- Server:Databricks クラスターのサーバーのホスト名に設定。
- Port:443
- TransportMode:HTTP
- HTTPPath:Databricks クラスターのHTTP パスに設定。
- UseSSL:True
- AuthScheme:PLAIN
- User:'token' に設定。
- Password:パーソナルアクセストークンに設定(値は、Databricks インスタンスの「ユーザー設定」ページに移動して「アクセストークン」タブを選択することで取得できます)。
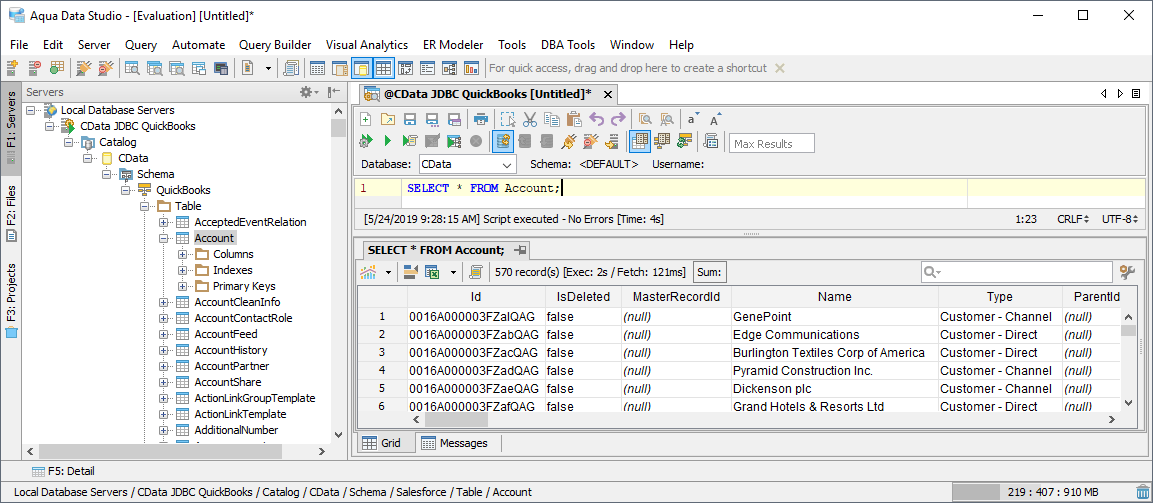
Spark のデータにクエリを実行
接続したテーブルにクエリを実行してみます。
![A query executed in the Table Data Editor.(QuickBooks is shown.)]()
関連コンテンツ