各製品の資料を入手。
詳細はこちら →Google BigQuery Driver の30日間無償トライアルをダウンロード
30日間の無償トライアルへ製品の詳細
Google BigQuery データ(テーブル、データセットなど)を組み込んだパワフルなJava アプリケーションを短時間・低コストで作成して配布できます。
CData


こんにちは!テクニカルディレクターの桑島です。
CData JDBC Driver for GoogleBigQuery は、JDBC 標準をインプリメントし、BI ツールからIDE まで幅広いアプリケーションでBigQuery への接続を提供します。この記事では、RACCOON からBigQuery に接続し、CSV 出力する方法を説明します。
下記の手順に従って、RACCOON のプロジェクト・フォーマット変換定義を作成し、BigQuery のJDBC 抽出処理を作成します。
まずは、本記事右側のサイドバーからGoogleBigQuery JDBC Driver の無償トライアルをダウンロード・インストールしてください。30日間無償で、製品版の全機能が使用できます。
ここから、必要なファイルの配置とプロジェクトの作成を行います。
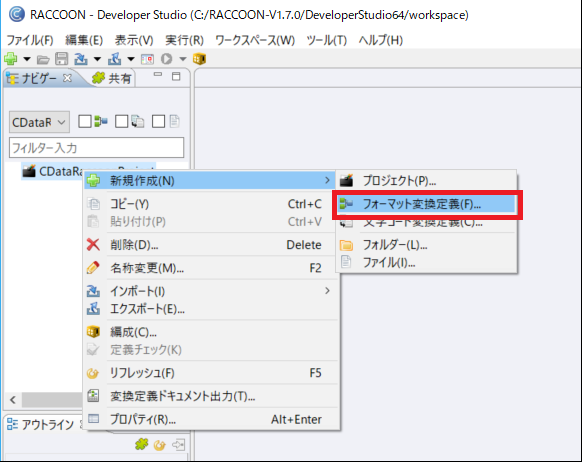
次にフォーマット変換定義を作成し、抽出処理を構成します。
jdbc:googlebigquery:DataSetId=MyDataSetId;ProjectId=MyProjectId;
入力後、[適用]をクリックします。
最後に抽出したデータの変換先として指定区切り子(CSV)の格納処理構成を行います。
このようにGoogleBigQuery 内のデータをプログラムやWeb APIの処理を記述することなくRACCOON 上で処理することができるようになります。
サポートされるSQL についての詳細は、ヘルプドキュメントの「サポートされるSQL」をご覧ください。テーブルに関する情報は「データモデル」をご覧ください。