Mµgen はIoT/ビッグデータ時代におけるデータ活用のための情報統合・分析プラットフォーム製品です。IoT 時代を迎えて、新しい世代のビジネスインテリジェンスシステムは企業内の多様なデータを IT 部門の最小限の支援で、ビジネス部門で自由に活用できることが要件です。8月に正式リリースとなるMµgen 2では、仮想データ統合から、ビジネスユーザーが自由に情報活用できる データブレンディング(データの組み合わせ)へと進化しました。CData JDBC Drivers を組み込んだことにより、社内に散在したExcel、CSV などのファイルから、Salesforce、SharePoint、NoSQL といった クラウド上のデータまで、ありとあらゆるデータの統合利用を実現しました。
Challenge:
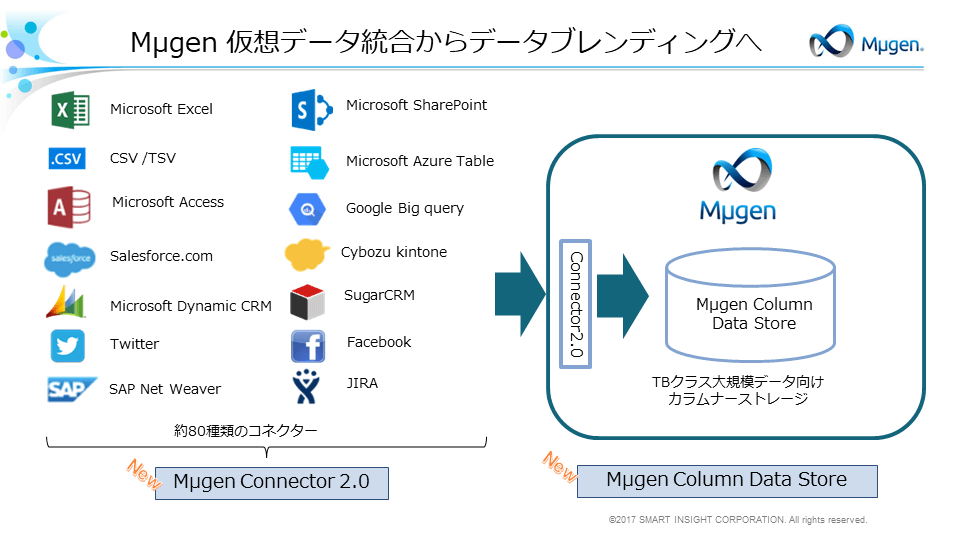
- サイロ化した、DB、CSV、SaaS、NoSQL データの統合
- テラバイト、ペタバイト規模のデータの高速かつ探索的な活用
Solution:
- CData JDBC Drivers をMµgenに組み込み、80以上のデータソースの利用を可能に
- データをテーブル形式でMµgen Column Data Store に格納し高速分析を実現
CData 本社のGent Hito (President)より、町田 潔 代表取締役社長にお話を伺いました。
Q: 企業顧客のデータ活用ニーズのトレンドはいかがですか?
町田氏: Mµgen は製造業、エンターテインメント業などの大手企業に利用されているデータ統合プラットフォームですが、急速にクラウドデータ統合のニーズが増えています。 SharePoint などのグループウェア、Salesforce、Dynamics CRM などのSFA/CRM、センサーデータやログなどのビッグデータを格納しているNoSQL データなどが蓄積されています。 ただし、せっかくのIoT などのデータもCSV のまま保管されているだけではビジネスに活かせません。サイロ化されたテラバイト、ペタバイトのデータの統合的な分析・活用が求められています。

Q: SMARTデータブレンディングとは?
町田氏: Mµgen は「データブレンディング」と位置付けています。データブレンディングとは、探索的にさまざまなデータを掛け合わせてそこからインサイト(気づき)を得て、 ビジネス戦略に活かすというものです。Mµgen のユーザーは、管理者や企画担当といった、データを扱い戦略立案をする立場の方々です。ある意味、こういうポジションや役割は日本企業に独特かもしれません。
そして大容量のデータを扱うため、サーバー型での運用がベストです。個々人のPC レベルではパフォーマンスが得られません。スマートインサイトでは、インドやアメリカに拠点を作って 現地のトレンドと日本の市場性を考え、Mµgen 製品の開発に至りました。
Q: CData JDBC Drivers を選択されたポイントは?
町田氏: CData の選定のポイントは、豊富な対応データソース、レポジトリしやすいテーブルデータへの抽象化です。CData では80を超えるデータソースへのJDBC ドライバー対応がされています。 クラウドサービスが増加する中、それぞれのAPI との連携を自社で組むことはほぼ不可能です。CData Drivers では統一されたインターフェースでの製品への組み込みが可能です。
またMµgen はテラバイトレベルの大規模データを扱うプラットフォームであり、ハイパフォーマンスなデータ探索・分析を行うためにはSaaS データもレポジトリに一度格納する必要があります。 CData Drivers では非構造化データも含めてWeb API をテーブルデータとして抽象化して提供してくれるため、RDB やCSV などと同じデータ構造のレポジトリを使うことでデータの統合利用を 容易に実現できます。

Q: クラウドデータ関連で次の動きは?
町田氏: 今回80を超えるデータソースの対応を数年前倒しで実現することができました。次はMµgen で生成したデータをオンプレミスだけではなく他のクラウドで再利用するためのMµgen のAPI の提供が 必要です。CData Software では、API の高速生成ツールを扱っており、API 構築での協業も進めていければと思います。



