 こんにちは、テクニカルサポートエンジニアの宮本です!
こんにちは、テクニカルサポートエンジニアの宮本です!
最近 G4という次世代のGoogle アナリティクスがリリースされ、徐々に使用されている方も増えてきているのではないでしょうか?
G4のトピックの一つとして、無償で BigQuery にデータを連携できる機能などがありますが、これまではというと大企業向けのプランである「アナリティクス360」でしか連携できませんでした。恐らく大多数の方は無料のスタンダードプランを使用していたかと思いますが、それでも BigQuery にデータを集約して扱いたいという方も多かったはずです。
そこで、今回は CData Sync というデータパイプラインツールを使って、昔から使われてる方のGoogle アナリティクスである「ユニバーサル アナリティクス」のスタンダードプランから、BigQuery にサイトコンテンツ情報を連携する方法をご紹介していきます。
CData Sync とは
クラウドサービスからデータベースへのノーコードレプリケートアプリケーションになります。レプリケートとは同期するという意味になりますので、CDataSync から接続できるクラウドサービスのデータをデータベースにまるっとコピーすることができます。
https://www.cdata.com/jp/
手順
それでは CDataSync をインストールからしていきますが、インストール部分はこちらの記事を参考にしてください。
www.cdatablog.jp
Google アナリティクスへの接続設定
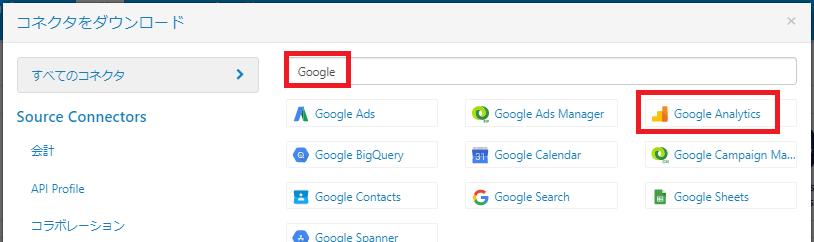
まずは Google アナリティクス のコネクタを CData Sync に追加するため、接続→データソース→+ Add More アイコンをクリックします。

Google と入力し、表示された Google アナリティクスのアイコンをクリックします。
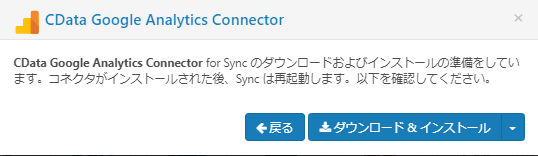
ダウンロード&インストールをクリックしてコネクタをインストールします。
インストールが完了するとCData Sync が再起動されますので、また接続設定画面に移動し、追加された Google アナリティクスのアイコンをクリックします。

Schema にUniversal Analytics を選択した後、右下にある「次に接続 Google Analytics」というボタンをクリックします。
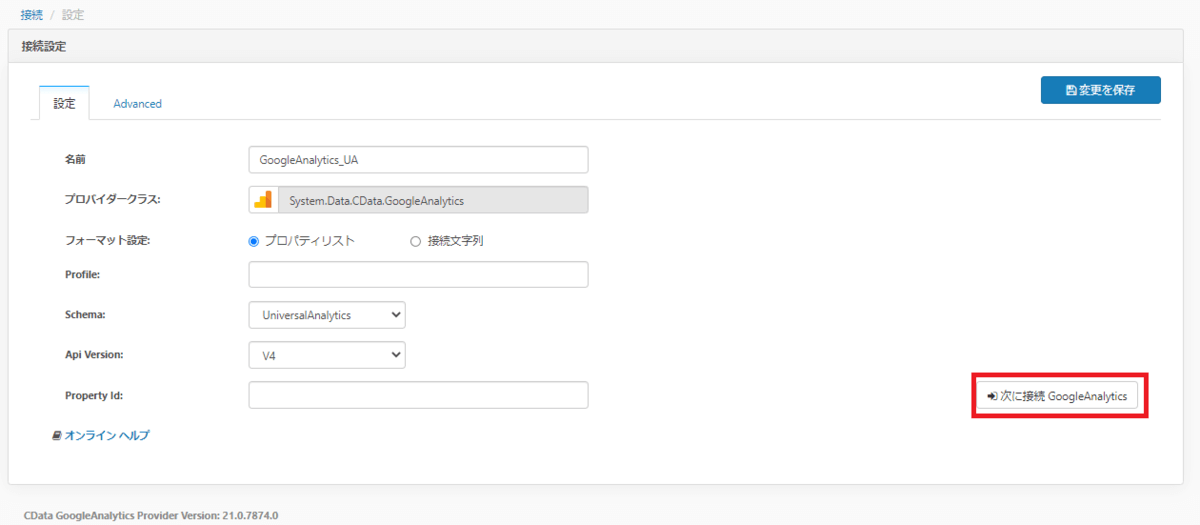
CData Sync の Google アナリティクスコネクタからのアクセスを許可します。
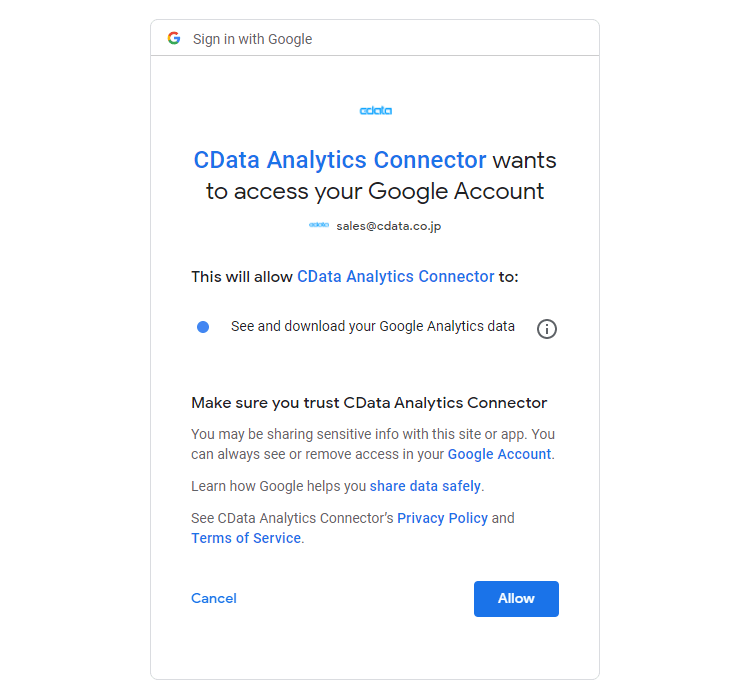
接続完了したら保存してGoogle アナリティクスへの接続設定が完了です。
BigQuery への接続設定
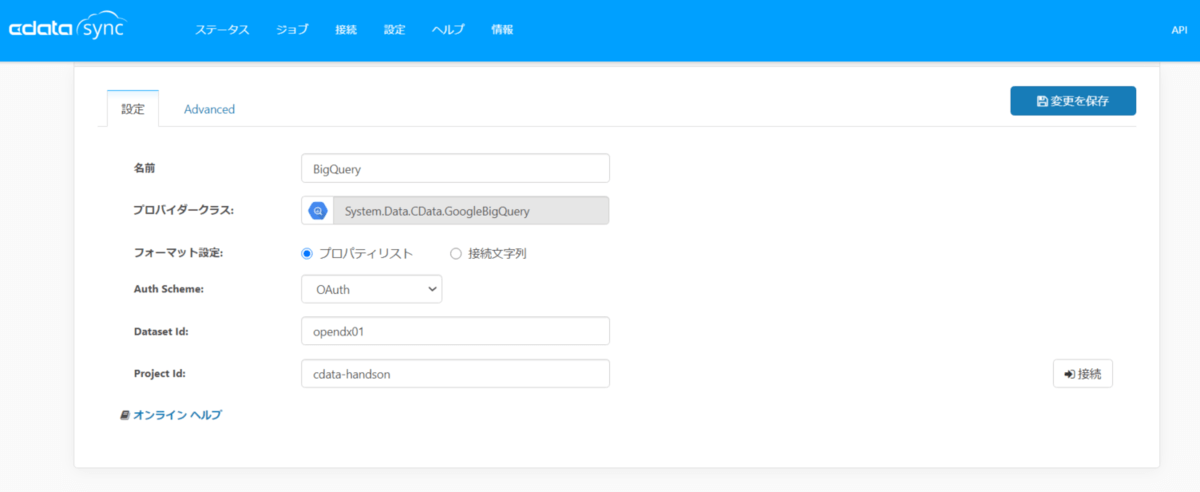
Sync では、レプリケートジョブを実行時に同期先DBに対してテーブルを自動で作成するようになりますが、その際に BigQuery の情報として必要なのがプロジェクトIDとデータセットIDになります。この情報を BigQuery のコネクション設定画面で入力していきます。
ヘッダーで「接続」をクリックして以下の画面を表示後、「同期先」→「BigQuery」の順でクリックしていきます。

今回、BigQuery への接続にはサービスアカウントを使用します。接続情報ファイルの内容をコピーして以下項目に設定お願いします。
【設定タブ】
Dataset Id:利用するBigQueryのデータセットID(RDBでいうスキーマ)
Project Id:GCP のプロジェクトID
【Advancedタブ】
Auth Scheme:OAuthJWT
OAuth JWT Cert: JSON形式のサービスアカウントキーのパス
OAuth JWT Cert Subject: *
OAuth JWT Cert Type:GOOGLEJSON
OAuth JWT Issuer: サービスアカウント名
入力完了後、設定タブに戻って右下の接続ボタン押下をクリック
接続テストが正常に完了した場合は、画面に緑色の帯でSuccessなどと表示されますので、右上の「変更を保存」で保存を行います。
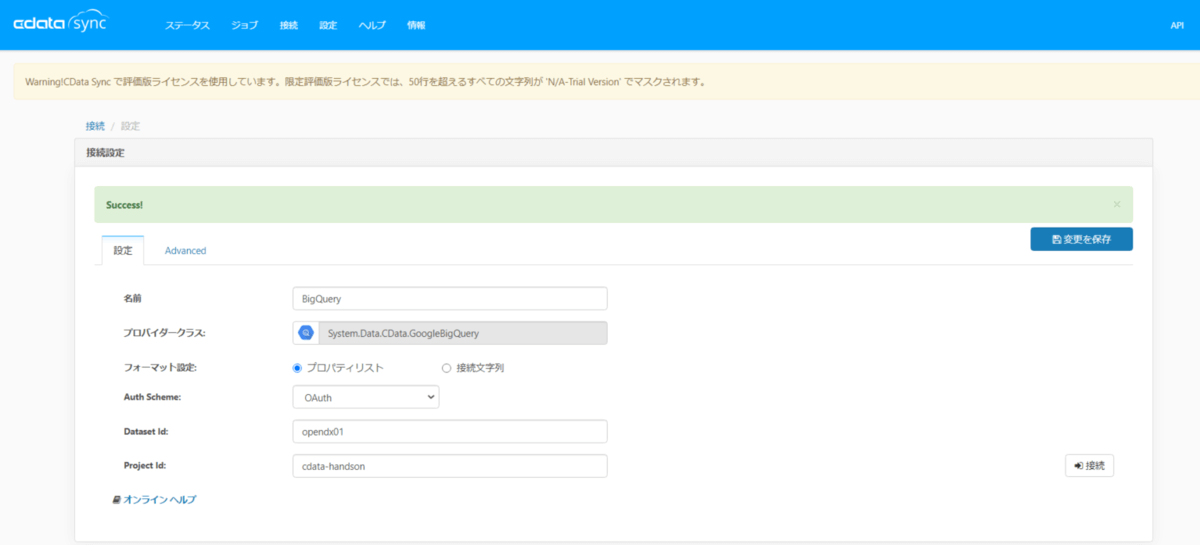
これでBigQueryのコネクション設定が完了です。
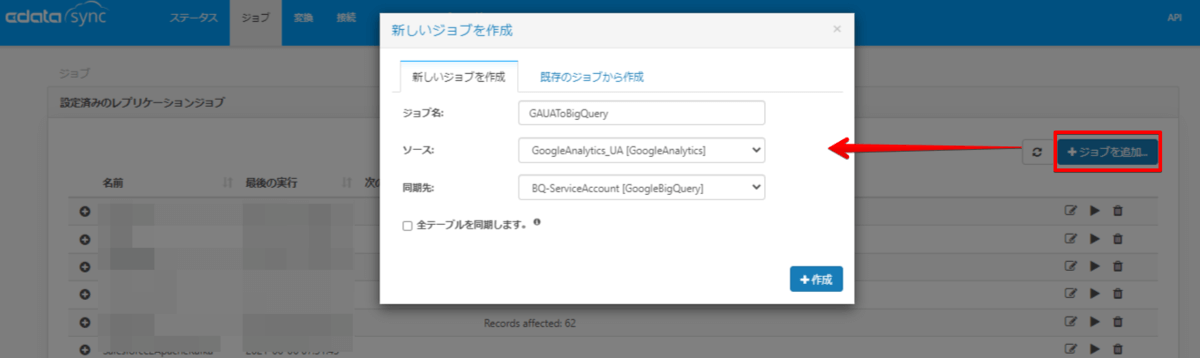
ジョブを作成
ジョブ画面で「ジョブを追加」から、ソースに Google アナリティクス、同期先に BigQuery を指定して作成ボタンをクリックします。
ひとまず「テーブルを追加」ボタンを押してみますと、16個のテーブルが表示されました。
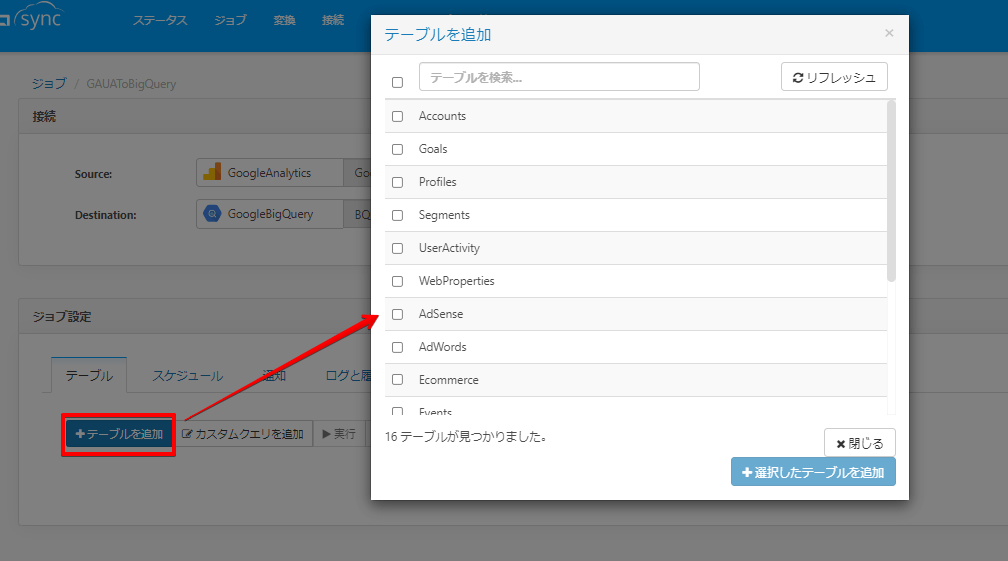
テーブル名とその中身については下記ヘルプをご参照ください。
https://cdn.cdata.com/help/DAG/jp/jdbc/pg_UniversalAnalyticsmodel.htm
あとは取得したいデータのテーブルを選択するだけで、BigQuery に作成されるテーブル名とクエリが自動的にセットされるようになります。
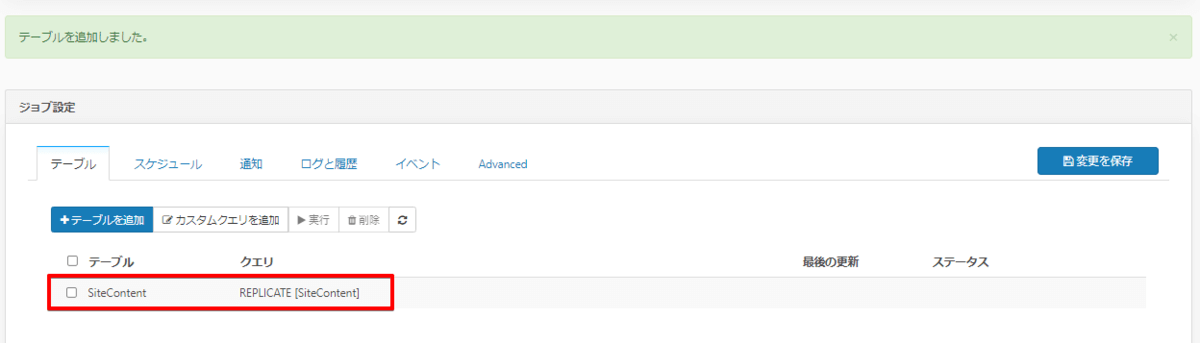
これでジョブの作成が完了です。
ディメンションと指標の指定
Google アナリティクスではデータを分析するための視点としてディメンションと指標を指定してします。
CData Sync の中では、1個のクエリで指標は10個、ディメンションは7個まで指定できます。すべての列を選択するクエリ(select * from)を発行すると、指標が10を超えるテーブルではデフォルトの指標列だけが選択されます。また、ディメンションについても明示的に指定しない場合は、デフォルトのディメンションが使用されます。(デフォルトのディメンションはヘルプにて確認できます)
例えば SiteContent テーブルの場合、赤枠の列がディメンションとなる項目で、指定がない場合は PagePath が指定されます。青枠についてはデフォルトの指標です。こちらも指定がない場合は、True となっている項目が自動的に内部で指定されます。
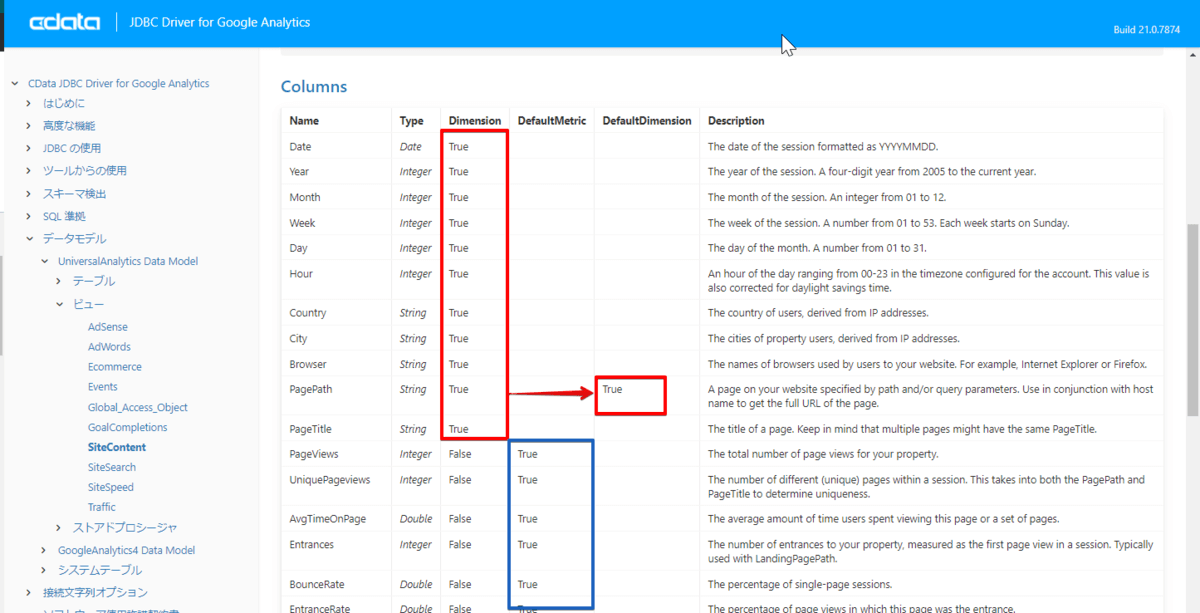 https://cdn.cdata.com/help/DAG/jp/jdbc/pg_UniversalAnalyticstable-sitecontent.htm
https://cdn.cdata.com/help/DAG/jp/jdbc/pg_UniversalAnalyticstable-sitecontent.htm
今回はディメンションに PageTitle、指標にSelect句のPageTitle 以外を指定してみたいと思いますので、先ほど作成したクエリをクリックします。
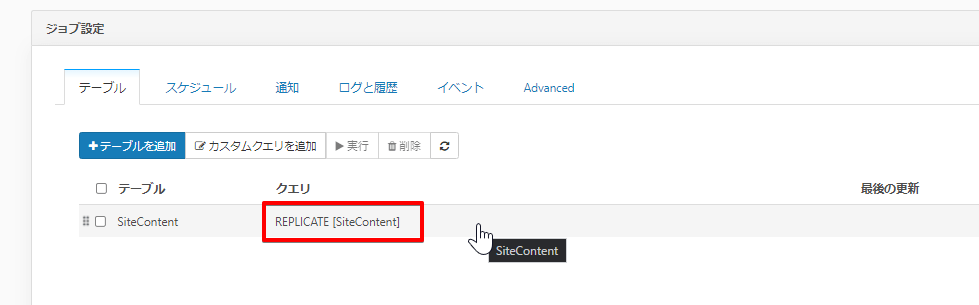
カラムマッピングタブにて、使用しない項目があれば矢印部分にカーソルを合わせると、バツ印が表示されますのでそのままクリックして対象外にすることができます。戻す場合は左側のカラム名のリストから選択します。
選択状況で画面下部のクエリが更新されていきます。
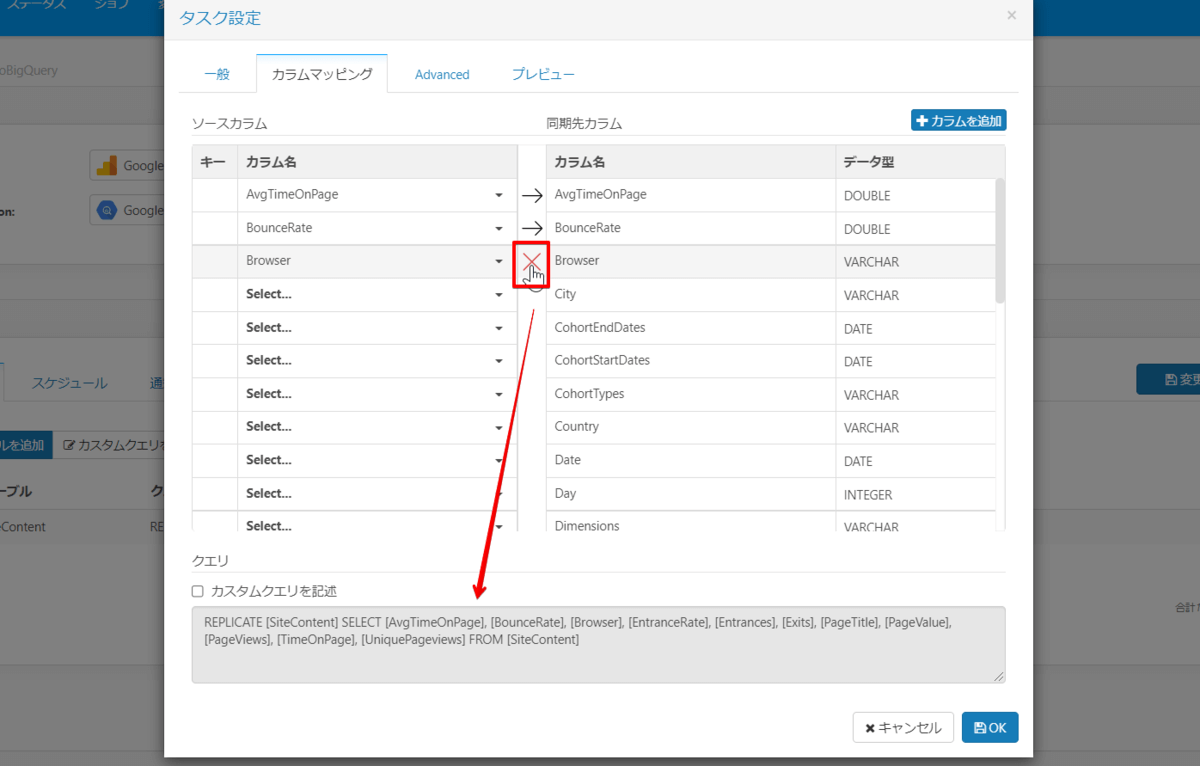
ちなみにクエリエリアで直接更新することもできます。選択式が面倒な場合はカスタムクエリを記述にチェックを入れ、下記クエリを貼り付けし、OKボタンをクリックします。
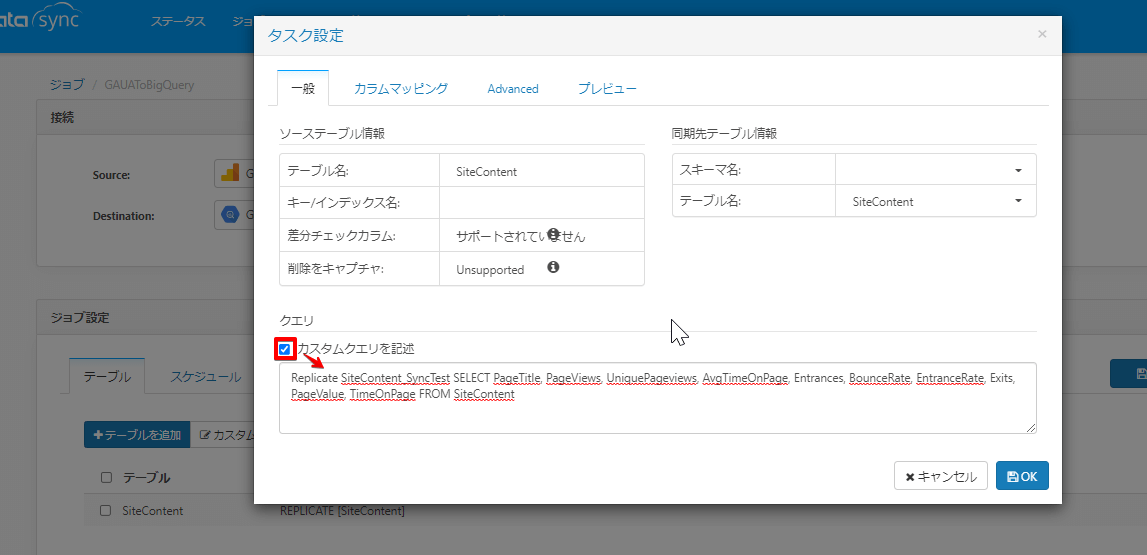
Replicate SiteContent_SyncTest SELECT PageTitle, PageViews, UniquePageviews, AvgTimeOnPage, Entrances, BounceRate, EntranceRate, Exits, PageValue, TimeOnPage FROM SiteContent
※Replicate SiteContent_SyncTest は、SiteContent_SyncTest というテーブルを同期先に作成するという意味で、必ず指定します。
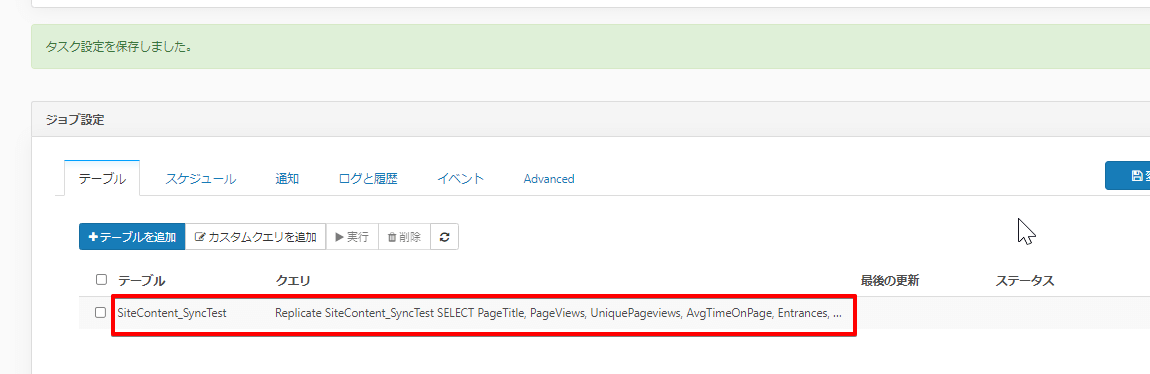
これでテーブル、クエリの部分が更新され、これで SiteContent_SyncTest というテーブルを BigQuery に作成してそこにデータを同期させていく準備ができました。
ジョブの実行
アドホックに行う手動実行とスケジューリング実行がありますが、今回は手動実行を行います。
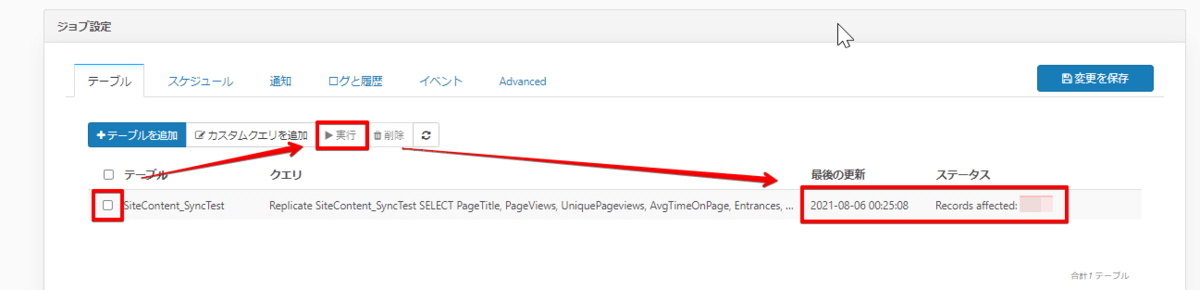
実行方法は当該クエリのチェックボックスにチェックをいれて実行ボタンをクリックします。少し待つと、最後の更新とステータス部分が更新されます。
エラーの場合はステータス部分にエラーメッセージが表示されます。
ジョブ実行結果の確認
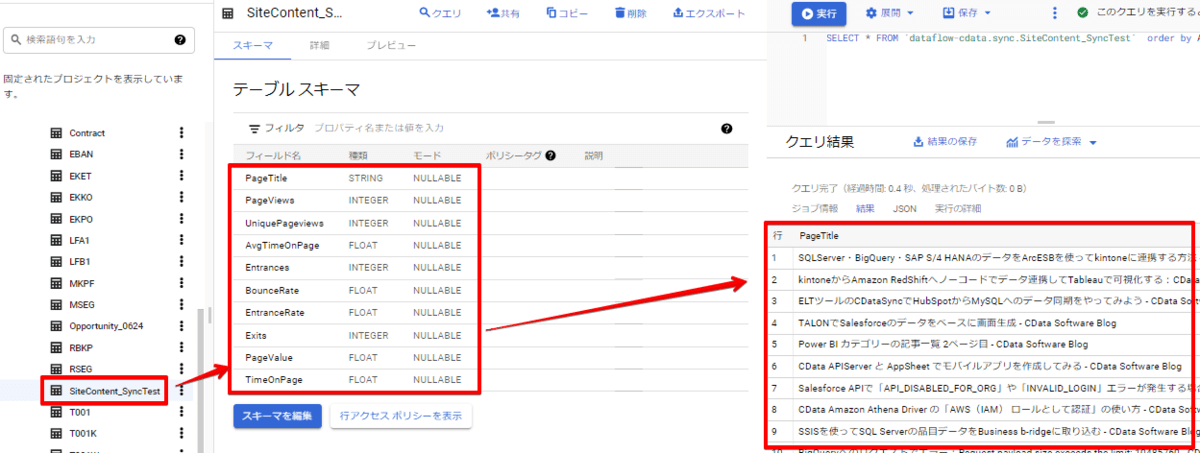
BigQuery のコンソール画面を表示させ、BigQuery への接続設定で指定したデータセットを開きます。そうすると、SiteContent_SyncTest というテーブルが作成されていることが確認できます。
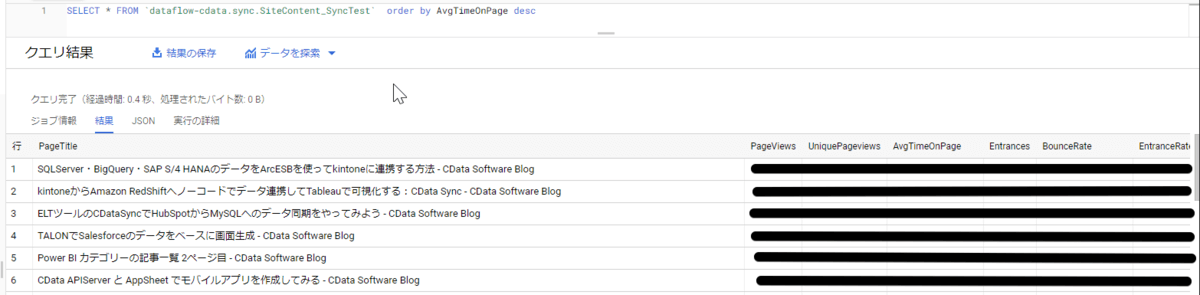
更にクエリを実行するとページタイトルを切り口に、指定した指標値となる項目の値がそれぞれ格納されているのが確認できます。
BigQuery に連携した後、更にいろんなサービス上で活用されていくかと思いますが、定番としては Google データポータルで使用する方法かと思います。
是非連携したGoogle アナリティクスデータをもとに活用ください。

おわりに
いかがでしたでしょうか。今回はGoogle アナリティクス(ユニバーサル アナリティクス)からBigQuery にサイトコンテンツ情報を連携するという方法をご紹介してみました。
CData Sync は 30日間のトライアルが可能です。是非お試しください!
www.cdata.com
関連コンテンツ



