Discover how a bimodal integration strategy can address the major data management challenges facing your organization today.
Get the Report →



Access Live Elasticsearch Data in AWS Lambda (with IntelliJ IDEA)
Connect to live Elasticsearch data in AWS Lambda using IntelliJ IDEA and the CData JDBC Driver to build the function.
AWS Lambda is a compute service that lets you build applications that respond quickly to new information and events. AWS Lambda functions can work with live Elasticsearch data when paired with the CData JDBC Driver for Elasticsearch. This article describes how to connect to and query Elasticsearch data from an AWS Lambda function built with Maven in IntelliJ.
With built-in optimized data processing, the CData JDBC Driver offers unmatched performance for interacting with live Elasticsearch data. When you issue complex SQL queries to Elasticsearch, the driver pushes supported SQL operations, like filters and aggregations, directly to Elasticsearch and utilizes the embedded SQL engine to process unsupported operations client-side (often SQL functions and JOIN operations). In addition, its built-in dynamic metadata querying allows you to work with and analyze Elasticsearch data using native data types.
About Elasticsearch Data Integration
Accessing and integrating live data from Elasticsearch has never been easier with CData. Customers rely on CData connectivity to:
- Access both the SQL endpoints and REST endpoints, optimizing connectivity and offering more options when it comes to reading and writing Elasticsearch data.
- Connect to virtually every Elasticsearch instance starting with v2.2 and Open Source Elasticsearch subscriptions.
- Always receive a relevance score for the query results without explicitly requiring the SCORE() function, simplifying access from 3rd party tools and easily seeing how the query results rank in text relevance.
- Search through multiple indices, relying on Elasticsearch to manage and process the query and results instead of the client machine.
Users frequently integrate Elasticsearch data with analytics tools such as Crystal Reports, Power BI, and Excel, and leverage our tools to enable a single, federated access layer to all of their data sources, including Elasticsearch.
For more information on CData's Elasticsearch solutions, check out our Knowledge Base article: CData Elasticsearch Driver Features & Differentiators.
Getting Started
Gather Connection Properties and Build a Connection String
Download the CData JDBC Driver for Elasticsearch installer, unzip the package, and run the JAR file to install the driver. Then gather the required connection properties.
Set the Server and Port connection properties to connect. To authenticate, set the User and Password properties, PKI (public key infrastructure) properties, or both. To use PKI, set the SSLClientCert, SSLClientCertType, SSLClientCertSubject, and SSLClientCertPassword properties.
The data provider uses X-Pack Security for TLS/SSL and authentication. To connect over TLS/SSL, prefix the Server value with 'https://'. Note: TLS/SSL and client authentication must be enabled on X-Pack to use PKI.
Once the data provider is connected, X-Pack will then perform user authentication and grant role permissions based on the realms you have configured.
NOTE: To use the JDBC driver in an AWS Lambda function, you will need a license (full or trial) and a Runtime Key (RTK). For more information on obtaining this license (or a trial), contact our sales team.
Built-in Connection String Designer
For assistance constructing the JDBC URL, use the connection string designer built into the Elasticsearch JDBC Driver. Double-click the JAR file or execute the jar file from the command line.
java -jar cdata.jdbc.elasticsearch.jar
")
Fill in the connection properties (including the RTK) and copy the connection string to the clipboard.
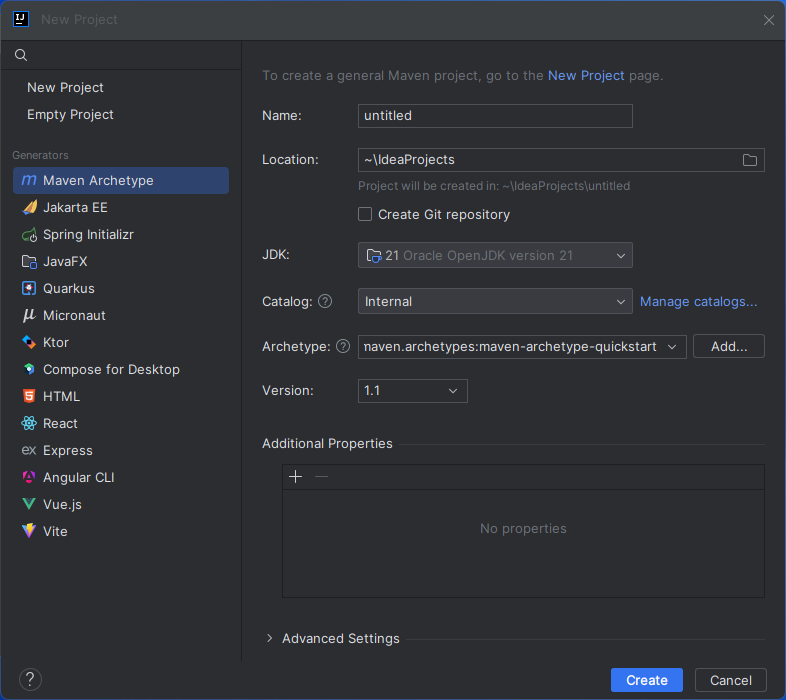
Create a Project in IntelliJ
- In IntelliJ IDEA, click New Project.
- Select "Maven Archetype" from the Generators
- Name the project and select "maven.archetypes:maven-archetype-quickstart" Archetype.
- Click "Create"
![]()
Install the CData JDBC Driver for Elasticsearch JAR File
Use the following Maven command from the project's root folder to install JAR file in the project.
mvn install:install-file -Dfile="PATH/TO/CData JDBC Driver for Elasticsearch 20XX/lib/cdata.jdbc.elasticsearch.jar" -DgroupId="org.cdata.connectors" -DartifactId="cdata-elasticsearch-connector" -Dversion="23" -Dpackaging=jar
Add Dependencies
Within the Maven project's pom.xml file, add AWS and the CData JDBC Driver for Elasticsearch as dependencies (within the <dependencies> element) using the following XML.
- AWS
<dependency> <groupId>com.amazonaws</groupId> <artifactId>aws-lambda-java-core</artifaceId> <version>1.2.2</version> <!--Replace with the actual version--> </dependency> - CData JDBC Driver for Elasticsearch
<dependency> <groupId>org.cdata.connectors</groupId> <artifactId>cdata-elasticsearch-connector</artifaceId> <version>23</version> <!--Replace with the actual version--> </dependency>
Create an AWS Lambda Function
For this sample project, we create two source files: CDataLambda.java and CDataLambdaTest.java.
Lambda Function Definition
- Update CDataLambda to implement the RequestHandler interface from the AWS Lambda SDK. You will need to add the handleRequest method, which performs the following tasks when the Lambda function is triggered:
- Constructs a SQL query using the input.
- Registers the CData JDBC driver for Elasticsearch.
- Establishes a connection to Elasticsearch using JDBC.
- Executes the SQL query on Elasticsearch.
- Prints the results to the console.
- Returns an output message.
- Add the following import statements to the Java class:
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import java.sql.SQLException; import java.sql.Statement; Replace the body of the handleRequest method with the code below. Be sure to fill in the connection string in the DriverManager.getConnection method call.
String query = "SELECT * FROM " + input; try { Class.forName("cdata.jdbc.elasticsearch.ElasticsearchDriver"); cdata.jdbc.elasticsearch.ElasticsearchDriver driver = new cdata.jdbc.elasticsearch.ElasticsearchDriver(); DriverManager.registerDriver(driver); } catch (SQLException ex) { } catch (ClassNotFoundException e) { throw new RuntimeException(e); } Connection connection = null; try { connection = DriverManager.getConnection("jdbc:cdata:elasticsearch:RTK=52465...;Server=127.0.0.1;Port=9200;User=admin;Password=123456;"); } catch (SQLException ex) { context.getLogger().log("Error getting connection: " + ex.getMessage()); } catch (Exception ex) { context.getLogger().log("Error: " + ex.getMessage()); } if(connection != null) { context.getLogger().log("Connected Successfully!\n"); } ResultSet resultSet = null; try { //executing query Statement stmt = connection.createStatement(); resultSet = stmt.executeQuery(query); ResultSetMetaData metaData = resultSet.getMetaData(); int numCols = metaData.getColumnCount(); //printing the results while(resultSet.next()) { for(int i = 1; i <= numCols; i++) { System.out.printf("%-25s", (resultSet.getObject(i) != null) ? resultSet.getObject(i).toString().replaceAll("\n", "") : null ); } System.out.print("\n"); } } catch (SQLException ex) { System.out.println("SQL Exception: " + ex.getMessage()); } catch (Exception ex) { System.out.println("General exception: " + ex.getMessage()); } return "query: " + query + " complete";
Deploy and Run the Lambda Function
Once you build the function in Intellij, you are ready to deploy the entire Maven project as a single JAR file.
- In IntelliJ, use the mvn install command to build the SNAPSHOT JAR file.
- Create a new function in AWS Lambda (or open an existing one).
- Name the function, select an IAM role, and set the timeout value to a high enough value to ensure the function completes (depending on the result size of your query).
- Click "Upload from" -> ".zip file" and select your SNAPSHOT JAR file.

- In the "Runtime settings" section, click "Edit" and set Handler to your "handleRequest" method (e.g. package.class::handleRequest)

- You can now test the function. Set the "Event JSON" field to a table name and click, click "Test"




Free Trial & More Information
Download a free, 30-day trial of the CData JDBC Driver for Elasticsearch and start working with your live Elasticsearch data in AWS Lambda. Reach out to our Support Team if you have any questions.
Ready to get started?
Download a free trial of the Elasticsearch Driver to get started:
Download NowLearn more:
Rapidly create and deploy powerful Java applications that integrate with Elasticsearch.
Data Connectors
ETL/ ELT Solutions
Cloud & API Connectivity
OEM & Custom Drivers